

This article refers to Strapi v4. For Strapi v5, use the resources below:
Core GraphQL API Documentation for Strapi 5
The official GraphQL API reference documentation covers queries, mutations, filters, sorting, and pagination for Strapi 5. This includes:
-
The new `documentId` usage instead of numeric `id`
-
Updated pagination patterns (both page-based and offset-based)
-
Relay-style queries with `_connection` suffix
-
Flattened response format without nested `data` and `attributes`
Migration Guides
- Strapi provides a step-by-step migration guide from v4 to v5 that includes specific instructions for GraphQL API updates:
GraphQL-Specific Migration:
- The dedicated breaking changes documentation for GraphQL API explains how to handle the flattened response format and Relay-style queries
Retro-compatibility Support:
- The GraphQL plugin documentation explains how to enable v4CompatibilityMode flag in the GraphQL plugin configuration to gradually migrate your code
Automated Migration Tools
- Strapi provides an upgrade tool with codemods that automatically handles some breaking changes.
Plugin Installation Updates
- The GraphQL plugin documentation shows the correct installation command for Strapi 5.
Breaking Changes Database
- Strapi maintains a comprehensive breaking changes database that lists all changes between v4 and v5, indicating which are handled by codemods and which affect plugins
Additional Resources
- Strapi v4 to v5 Migration Resources - FAQ and common topics
Sort and Pagination (REST API) - REST API pagination patterns that parallel GraphQL
Strapi is an open-source headless CMS for creating quick and readily-manageable APIs. It allows developers to create flexible API structures with a beautiful user interface easily. It is also self-hosted, meaning you can build your APIs in the UI, and Strapi will still host and server the API endpoints for you. You can push your Strapi server to any cloud host for the world to use your APIs.
APIs are built-in Strapi in the name of collections, although they now support single-type APIs.
For example, if we create a collection called Animals, Strapi will provide us with the following endpoints:
/api/animalsGET: This endpoint will return all the animals on the server./api/animals/:idGET: This will return a specific animal from the server using the id to find the animal. The id is a globally unique identifier the server sets to identify/marl each animal resource in the back-end uniquely./api/animals/:idPUT: This edits an animal resource in the collection. The id is the id of the animal to edit. This request body will contain the new info about the animal that will be edited./api/animals/:idDELETE: This endpoint deletes/removes an animal from the collection./api/animalsPOST: This endpoint adds a new animal to the mix. The request body will contain the data of the new animal to be created.
That's the power of Strapi, we don't have to write the code for each endpoint, and we don't have to set up any database; everything is provided for us from the start.
Strapi has plugins and configurations that enable us to add extra custom features to Strapi. For example, you can add a database (PostgreSQL, MySQL, etc.). This will make Strapi use your database instead of its inbuilt DB.
Strapi is very flexible and allows developers to configure the back-end to their liking easily.
Prerequisites
We will need a few tools installed on our machine for this article.
- Node.js: Strapi and React.js all run on Node.js. So we must have Node.js installed on our machine. You can download it from here Node.js download page.
- NPM: This is the official Node package manager. It comes bundled with the Node.js binaries.
- A Text Editor: Preferably, Visual Studio Code. You can download it from here.
What is Pagination?
Pagination is the breaking up of web data into discrete parts. This optimization technique requires the whole page to be broken up and delivered into pages.
For example, a news app can have up to 10,000 news in its backend. Thus, displaying the news in one fell swoop will significantly impact client and server performance.
It will take time for the server to get all 10K news posts and send them to the client. The payload will be massive, and it will cause latency and high network usage on the server.
On the client side, the news post requests will take time for the response to reach the client, so there will be a huge load time. Then, whenever the response comes, the UI framework will loop through the 10K news posts and render them on the UI. The looping alone will have a performance problem on the JS engine, then combine it with the rendering of each news post up to that large number.
Our browser might become unresponsive when it loops and renders 10K news posts. The solution is to collect the news posts from the server chunk by chunk. We will request a small chunk of the dataset, render it, and when the next dataset is needed, a request is sent, and the next chunk in-line is sent from the server. We will render the whole dataset in the browser without affecting the performance. Doing is called pagination.
The 10K news posts are broken into pages. A page represents a chunk or slice of the datasets rendered at a time.
Since we have 10K records, and we want 20 records in a chunk, that means we will have 500 pages (10,000/20). Each page will have 20 records. We can set the limit, which will require re-calculating the number of pages that it will generate because changing the limit of records to 10 records will mean that our news app will have 1000 (10,000/10) pages. In the next section, we will look into the types of pagination.
Types of pagination
There are two types of ways we can achieve pagination. They are:
- Offset-based pagination
- Cursor-based pagination
Let's start with offset-based pagination.
Offset-based pagination
Offset-based pagination uses the concept of start and limits to get discrete parts from the database.
The process involves setting the number of records to fetch and the number of records to skip. This is usually done by using the limit and offset.
The limit sets the number of records to return. The offset specifies the index from where the record collection/fetching will start.
For example, we have this dataset.
0. data_1
1. data_2
2. data_3
3. data_4
4. data_5
5. data_6
6. data_7
7. data_8
8. data_9
9. data_10
10. data_11
11. data_12
12. data_13
13. data_14Each record has a unique global identifier, no two records can have the same identifier. Therefore, we can fetch the data in discrete parts by specifying the index in the datasets to start from and the maximum amount to return.
For instance, we want to get five items per request. So, we send the request along with limit and offset values in the initial request.
limit: 5
offset: 0The index of the first record is zero
This will start with the 1st record data_1 and take the following four records. The result will be:
0. data_1
1. data_2
2. data_3
3. data_4
4. data_5Now, on the next request, the limit and values will be:
limit: 5
offset: 5This will start with the 6th record and get the next four records. The result will be:
6. data_6
7. data_7
8. data_8
9. data_9
10. data_10This result is appended to the previous result and displayed on the UI. These techniques do away with the performance bottleneck we experienced before when fetching the whole data. Now we won't experience any unresponsive UI, and the load time will be much lesser because each response will have a small payload size. The data are fetched in batches, and each batch contains a small subset of the whole dataset.
Coming from an SQL background, we can use clauses in SQL to fetch rows from tables in batches.
SELECT column FROM table LIMIT 10 OFFSET 10The LIMIT states the number of rows to retrieve/return from the table. The OFFSET tells the SQL engine to start from the 11th row in the table. With the above SQL statement, we have achieved offset-based pagination in SQL.
Problems with offset-based pagination
Problems occur when data are inserted and removed from the datasets while the pagination continues. Offset-based pagination uses an index, which is the record's position in the list. When a record is removed from the list, the indexes change.
For example, in our data list above, if data_1 is removed, the indexes change, and it affects the next set of records to be fetched because offset pagination works on the indexes. This results in missing records or duplicates records.
Cursor-based pagination
Since indexes in offset-based pagination are not reliable, we can identify the records directly in the datasets and use them as a pivot point. This point of pivot is the cursor, hence the name cursor-based pagination.
The point of pivot/cursor must be globally unique to all records in the dataset. This is useful, so even if duplicate records exist in the dataset, their unique IDs will stand out. IDs are usually used as the cursor because it is sequential and unique.
Cursor-based pagination involves selecting a specific record from the dataset and then collecting the following nth records. Unlike offset-based pagination, which uses an index in the dataset, cursor-based pagination uses the field in the record.
A request in cursor-based pagination will be like this:
cursor: 2
limit: 5Using id as the cursor in the records field. This request will start from the record with an id field with two and collect the next four records.
In SQL, cursor-based pagination will look like this when getting from a blogPosts table:
select * from blogPosts where id > 0 limit 2This statement will select blog posts from the blogPosts table starting from the record whose id field is greater than 0. Thus, the maximum number of blog post rows to select is two records only.
The blogPosts table is this:
{ id: 1, post: "Post_1"},
{ id: 2, post: "Post_2"},
{ id: 3, post: "Post_3"},
{ id: 4, post: "Post_4"},
{ id: 5, post: "Post_5"},
{ id: 6, post: "Post_6"},
{ id: 7, post: "Post_7"},
{ id: 8, post: "Post_8"},
{ id: 9, post: "Post_9"},
{ id: 10, post: "Post_10"}The result will be this:
{ id: 1, post: "Post_1"},
{ id: 2, post: "Post_2"},On the next request, we will increase the value to fetch rows whose id field value is greater than
-
This is because the last record in our result has an
idof 2.select * from blogPosts where id > 2 limit 2
Let’s look at how we achieve pagination in a GraphQL API.
Pagination and GraphQL
GraphQL is an open-source query language for data APIs created by Facebook in 2012. It uses the concept of a query (read), mutation (write), and subscription (continuous read) to fetch data from an API.
GraphQL is a runtime in the backend. This runtime provides a structure for servers to describe the data to be exposed in their APIs. Clients can then write the structure of data they want from the server using the GraphQL language. Finally, the language text is sent to the GraphQL server via the HTTP POST request.
The GraphQL runtime receives the GraphQL language, runs it, puts together the data as requested, and sends it back to the client.
Note: following examples are general GraphQl examples and not specific to Strapi. We will cover that later in the tutorial.
A simple Graphql query looks like this:
query {
posts {
data {
title
body
}
}
}This tells the GraphQL runtime to give us an array of posts, on each post record, we want the title and body fields present.
{
"data": [
{
"title": "Intro to React",
"body": "Body content of React"
},
{
"title": "Intro to Angular",
"body": "Body content of Angular"
},
{
"title": "Intro to Vue",
"body": "Body content of Vue"
},
{
"title": "Intro to Svelte",
"body": "Body content of Svelte"
},
{
"title": "Intro to Preact",
"body": "Body content of Preact"
},
{
"title": "Intro to Alpine",
"body": "Body content of Alpine"
}
]
}If the number of post records in our GraphQL server is huge, we will experience lag and poor performance.
How do we employ pagination in GraphQL?
It seems complex to do with all those weird language structures used to fetch data. Yes, but it is simple to achieve.
The limit and offset arguments are used to implement offset-based pagination in GraphQL endpoints.
The limit sets the number of records to return from the endpoint. The offset sets the index in the dataset to start from.
query {
posts(limit: 2, offset: 7) {
data {
title
body
}
}
}The query above will start from index 7 in the record list and return two records below it. To get the next records, we know that the next index to start is 9. the query will be this:
query {
posts(limit: 2, offset: 9) {
data {
title
body
}
}
}The next query will be from offset 11:
query {
posts(limit: 2, offset: 11) {
title
body
}
}From the query resolver, we will have to get the limit and offset args and use them to return the records.
- Example: Query: { posts: (parent, args, context, info) => {}; }
The args param will have the arguments in our query in its object body. So we destructure them:
Query: {
posts: (parent, args, context, info) => {
const { limit, offset } = args
...
};
}Then, we use them to get the data in discrete parts.
const postArray = [];
Query: {
posts: (parent, args, context, info) => {
const { limit, offset } = args;
return postsArray.slice(offset, limit);
};
}We have our DB in an array, so we use the Array#slice method to get the posts off the postsArray using the limit and offset as the starting index and the amount to slice, respectively.
The main point here is that we have the limit and offset arguments. We can then use them to get records in parts from our database (e.g., PostgreSQL, MySQL, in-memory database, etc.)
That's a simple way to achieve offset-based pagination in GraphQL.
To implement cursor-based pagination in GraphQL, we use the cursor and limit arguments. The argument's names can be whatever you want in your implementation, and we chose these names to describe what they do.
A query will be like this:
query {
posts(cursor: 4, limit: 7) {
data {
title
body
}
}
}The cursor is set to 4, the id of the record in the dataset to start from, and the limit is the number of records to return.
We know the cursor is not always the id of the records in the list. The cursor can be any field in your records; the important thing is that the cursor should be globally unique in your records.
Strapi supports GraphQL, and this is done by installing the GraphQL plugin to the Strapi mix.
With the Strapi GraphQL, we can use Strapi filters start and limit filters to achieve offset-based pagination in our Strapi endpoint. Now, we build a GraphQL Strapi API to show how to use pagination in GraphQL-Strapi.
Scaffold Strapi project — Newsfeed app
First, we will create a central folder newsapp-gpl:
mkdir newsapp-gplMove into the folder and scaffold the Strapi project.
cd newsapp-gplwe will scaffold a Strapi project
npx create-strapi-app@latest newsapp-gpl-api --quickstartThe above command will create a Strapi folder newsapp-gpl-api and also start the Strapi server at localhost:1337. This is the URL from which we can build our collections and call the collections endpoints.
Strapi will open a page to register an admin before we can start creating endpoints: http://localhost:1337/admin/auth/register-admin.
Now, by default, Strapi creates REST endpoints for the collections. To enable the GraphQL endpoint, we will have to add the GraphQL plugin.
To do that, we run the below command:
➜ newsapp-gpl-api yarn strapi install graphqlRe-start the server to save changes.
Open the link http://localhost:1337/graphql. The GraphQL playground will open up.
Now, we can’t perform any op (query or mutation).
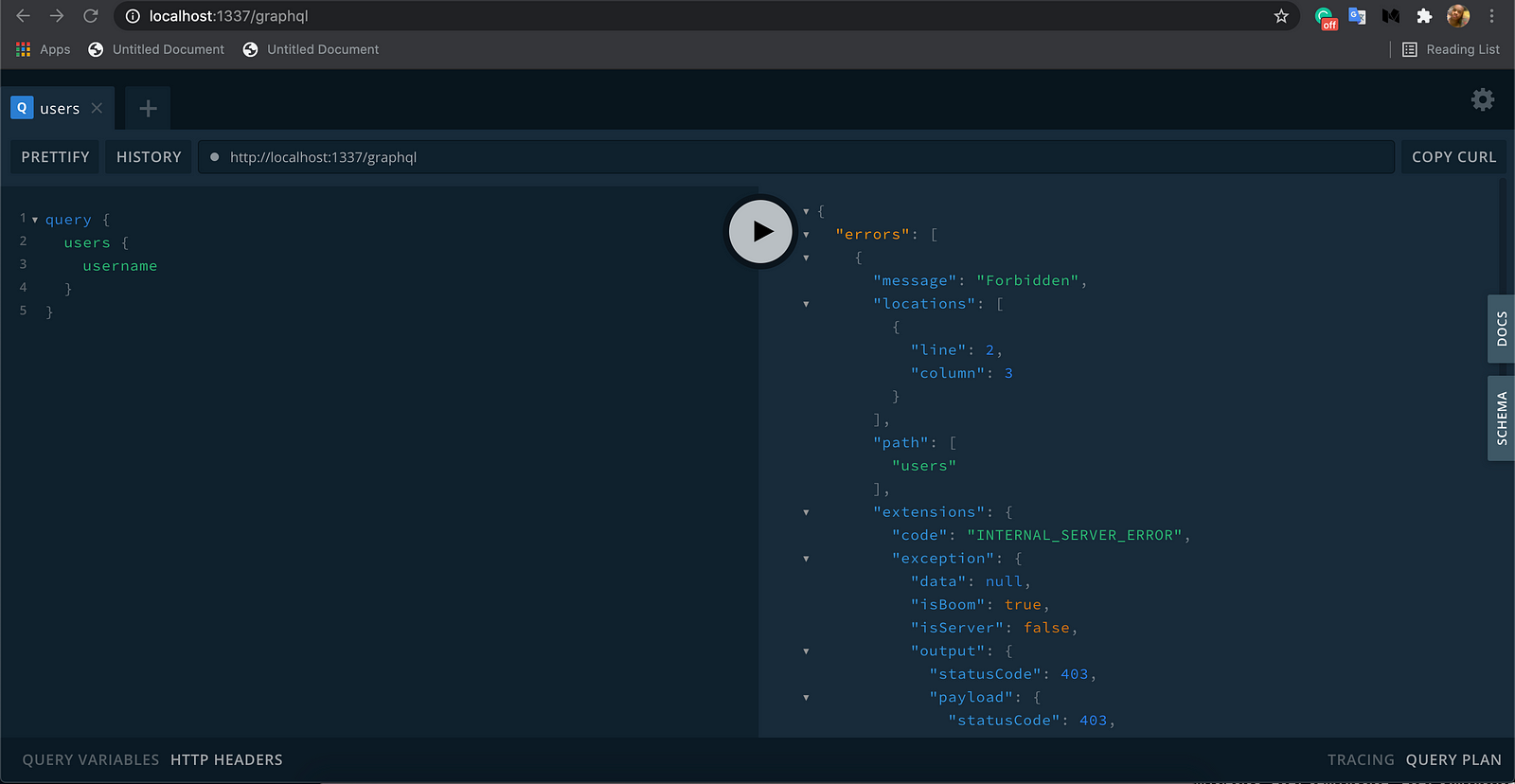
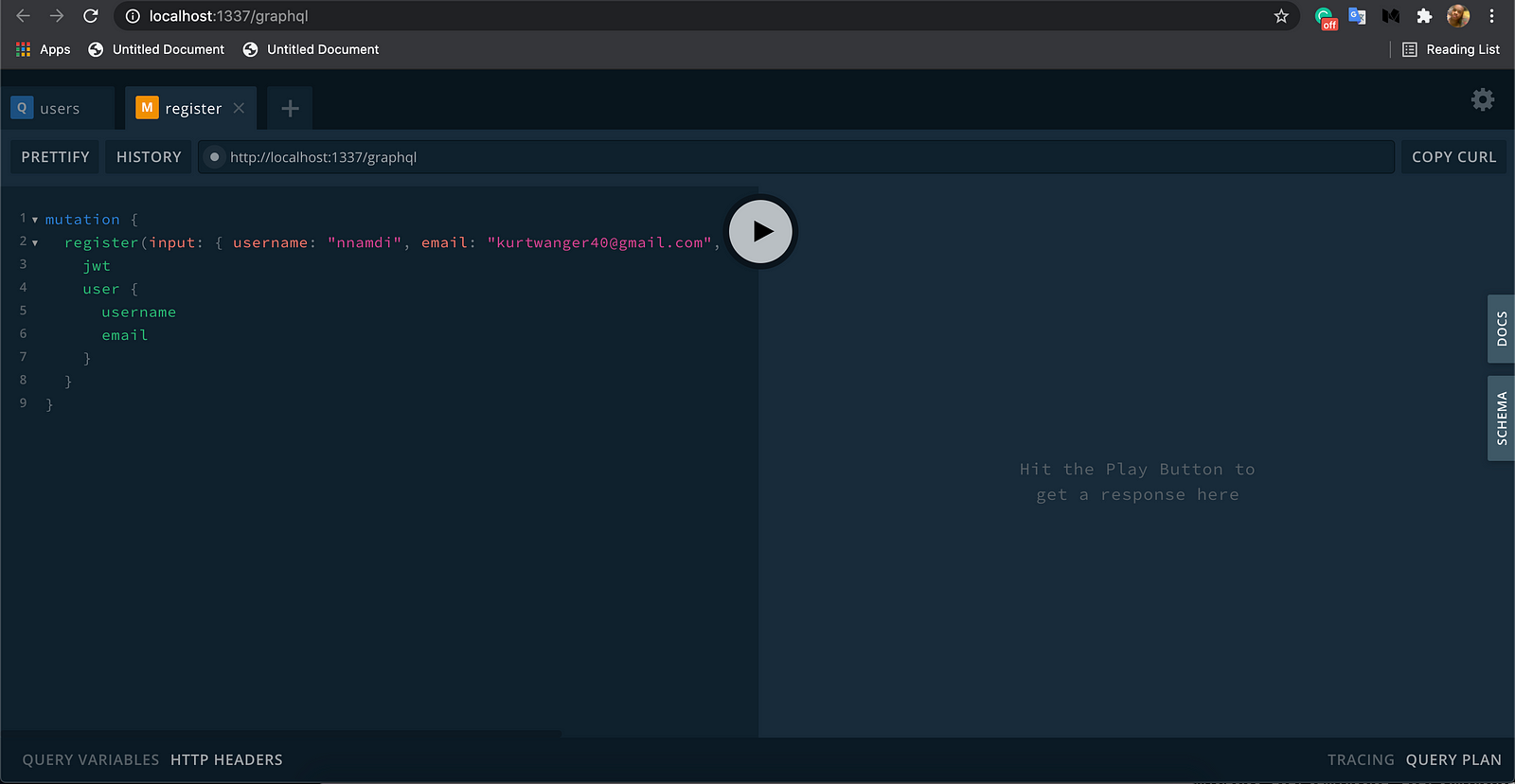
We must register ourselves before we can do anything. Open a new tab in the playground and run the below mutation:
mutation {
register(input: { username: "nnamdi", email: "kurtwanger40@gmail.com", password: "nnamdi" }) {
jwt
user {
username
email
}
}
}
See the result:
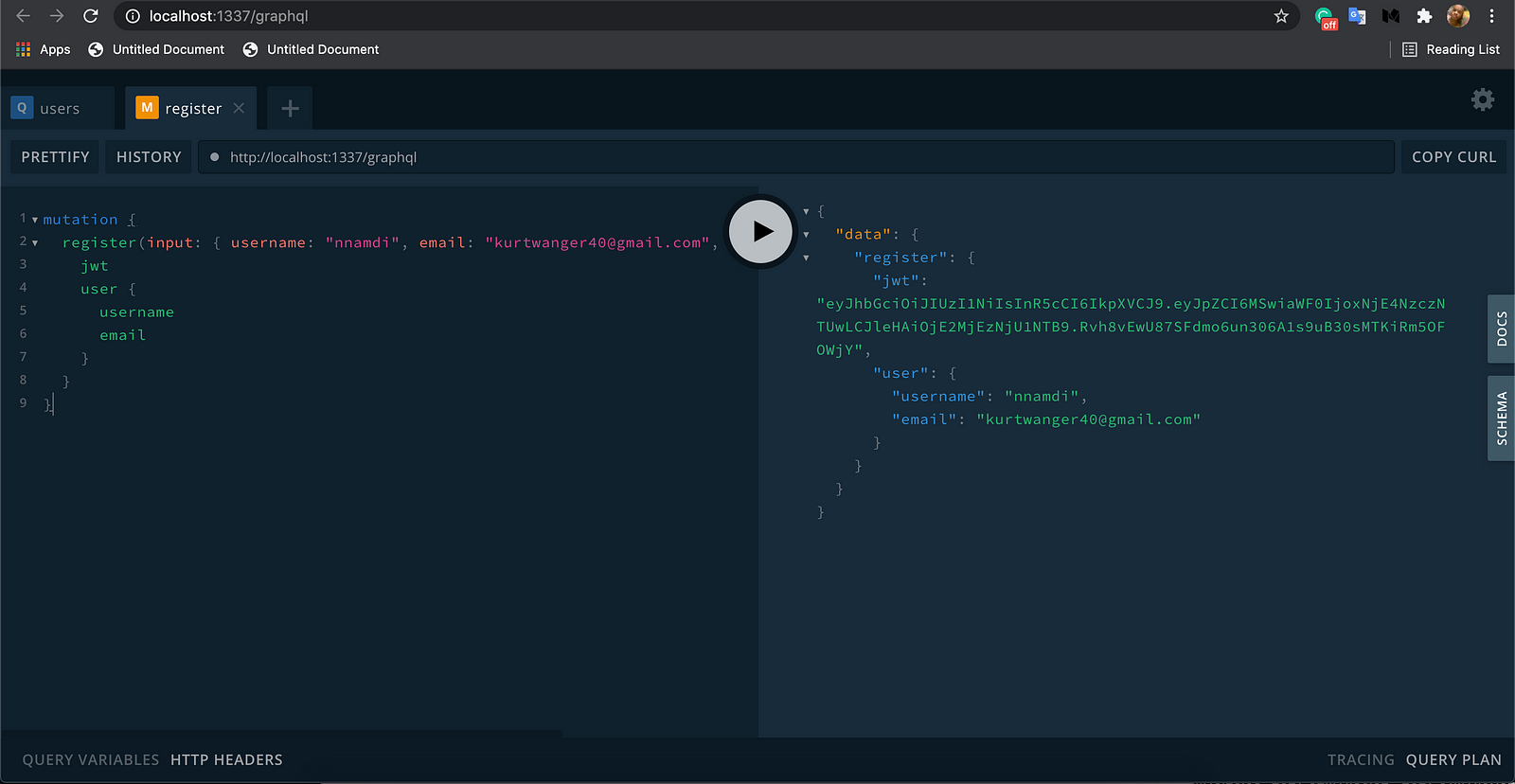
This will create a new user in the User collection type in our admin panel.

Creating the Content Model
Now, we will create a Content Model named News Posts. To do this, we will click on Content-Type Builder in our Strapi's admin panel and click on Create new collection type.

Next, we will give the collection a name. You can decide to name it anything you like but in this tutorial, the name is News Post.

Now, configure the collection as shown using the following:
title -> Text, Short text
body -> Text, Long text
image -> Text, Short text
writtenBy -> Text, Short textOnce we are done configuring the collection, we will have an output similar to the one shown below. Click on Save and let Strapi restart the server.

Then, populate the collection with news data. Add data up to 15 items.
Strapi will not generate REST endpoints for our News Post collection. Instead, it will create GraphQL mutations and queries for the News Post collection.
We have to enable role access for the News Post collection. Go to "Settings" -> "Roles" -> "Public". Enable "Select all" for newsPost. Then, scroll up and click on "Save".

Setting up React
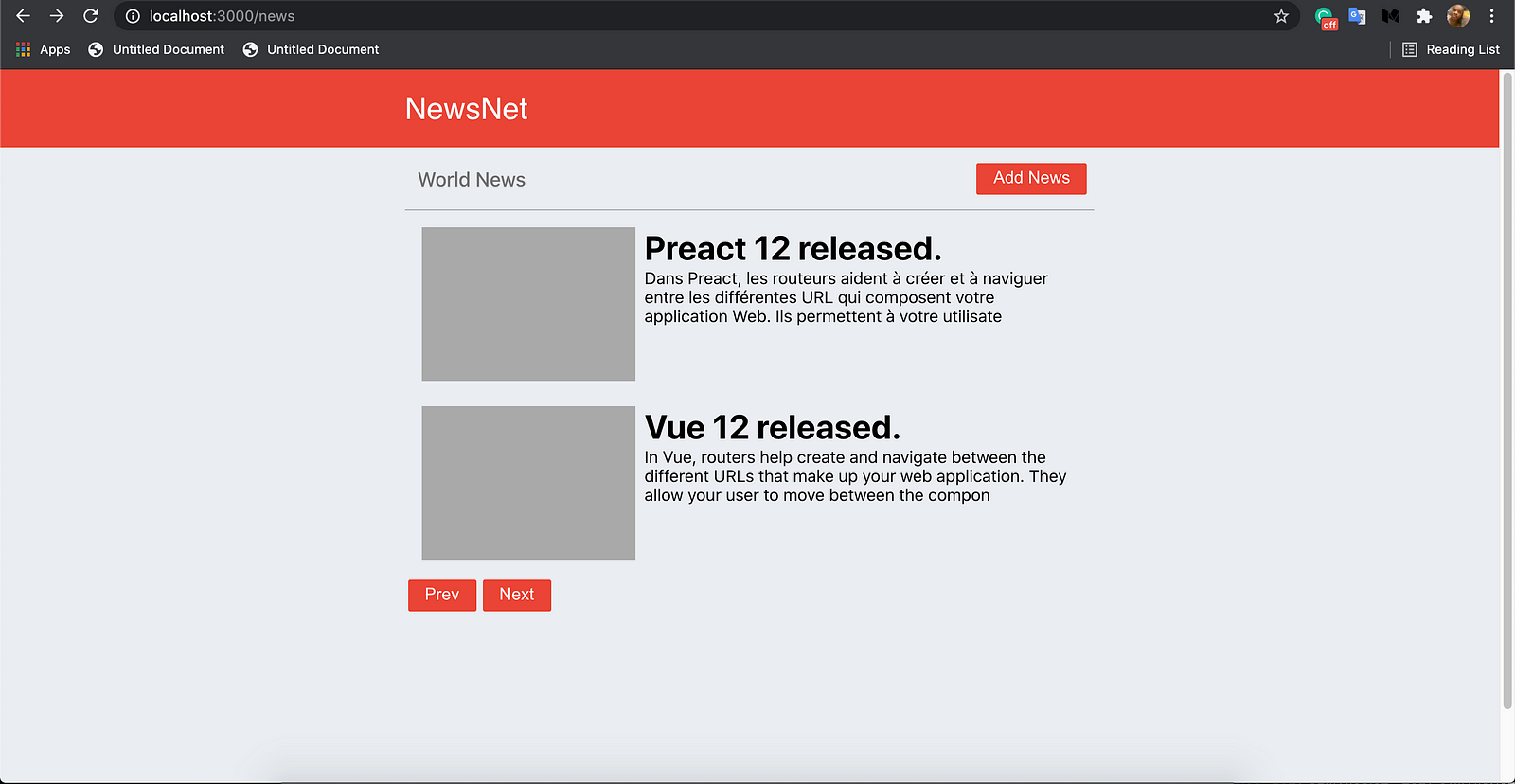
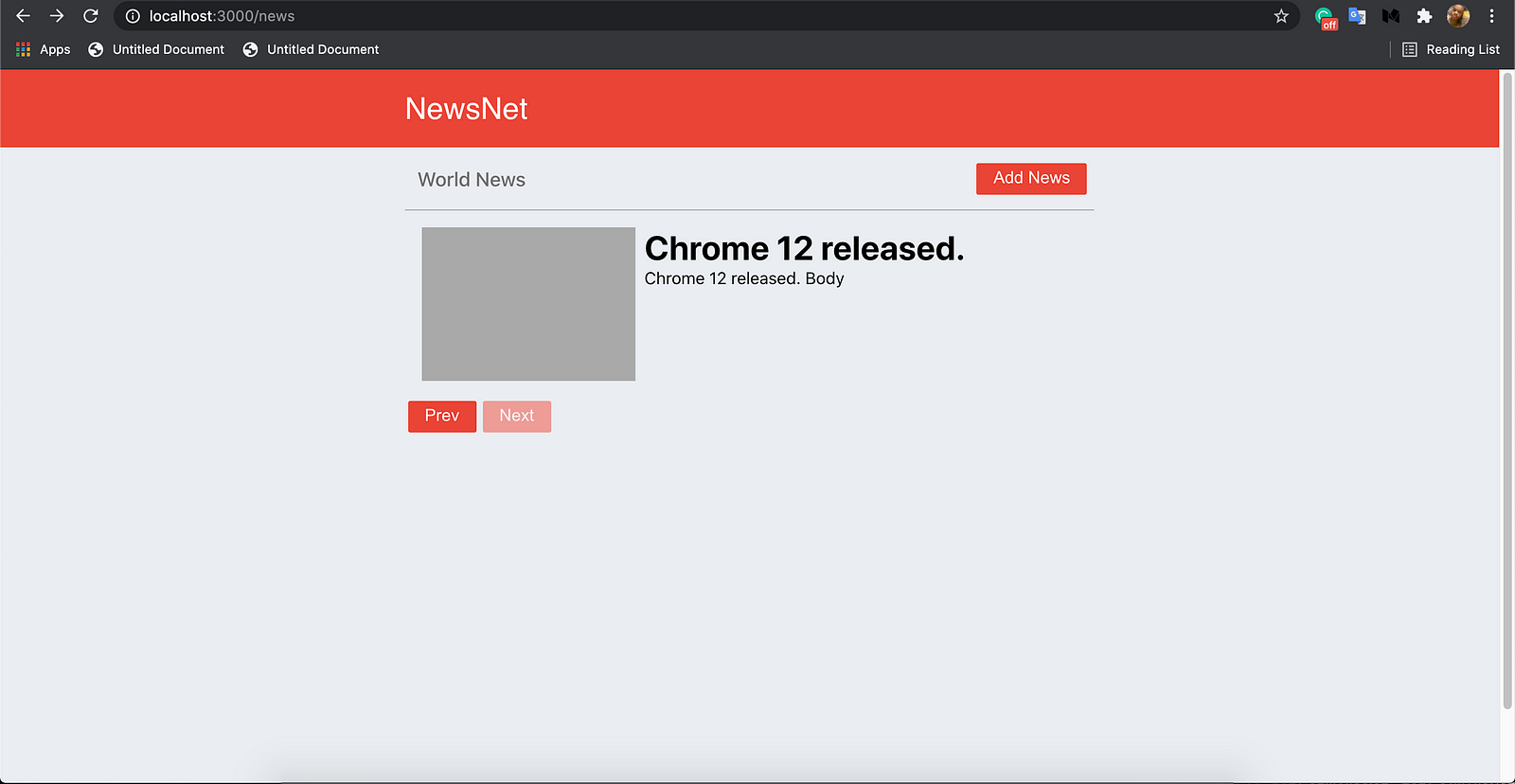
Here, we will build a news app using React.js. This app will display all the news in our back-end in a list. We will paginate the news list in a form with "Next" and "Prev" buttons. These buttons will be used to navigate the pages of the news list.
The news list page will display a maximum of two news posts per page. If the "Next" button is pressed, it loads the next page. Likewise, if the "Prev" button is pressed, it loads the previous page.
We will use a React starter file for this project to concentrate more on the Graphql aspect.
Our app will look like this:
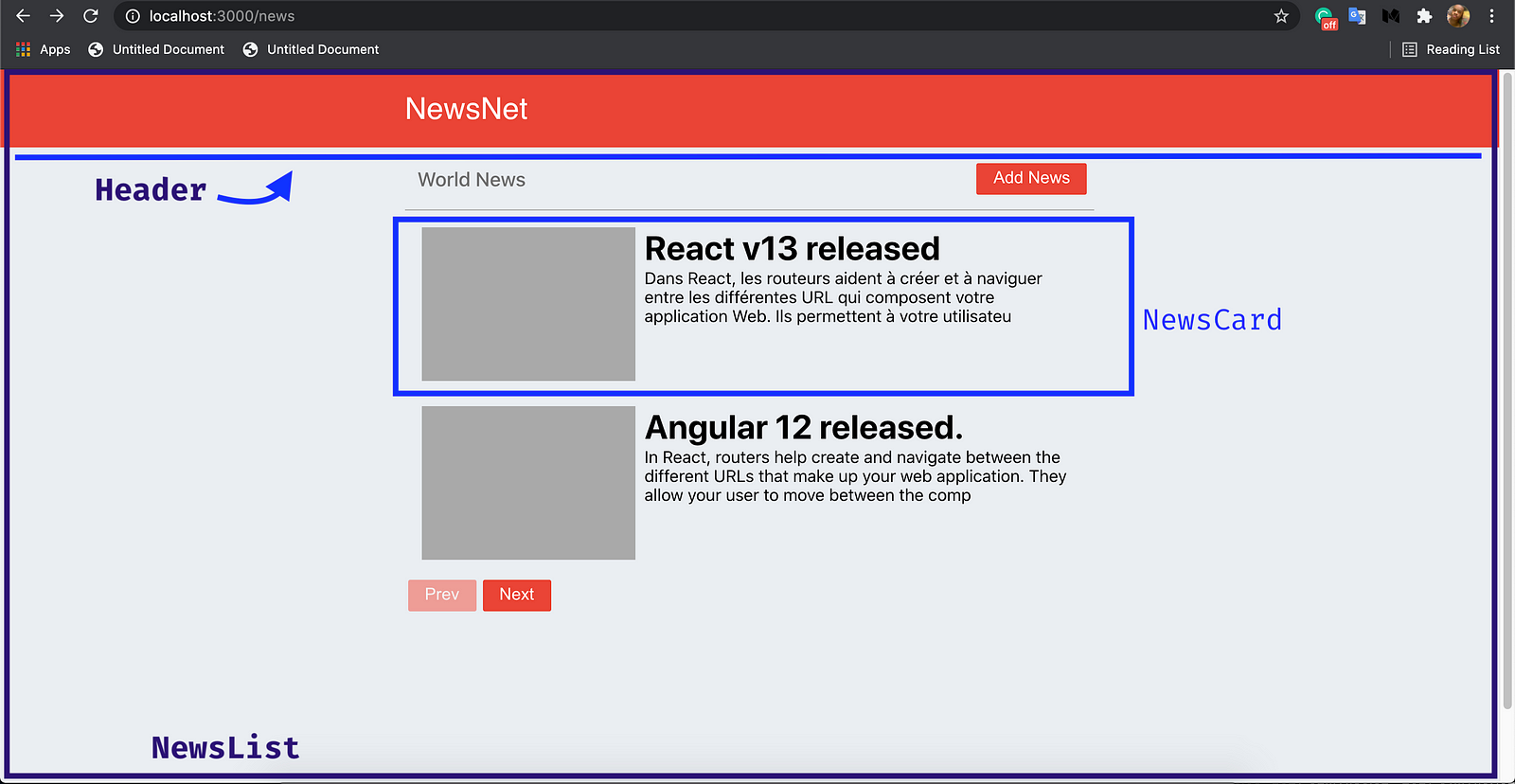
It will have the following components:
- Header: This will hold the header section of our app.
- NewsListPage/NewsListOffset: This component will be a page component. It will be rendered when we navigate to the /news route. It will display the list of news. It is an intelligent component.
- NewsCard: This component will display an overview of a news post. The NewsList component will render it.
- NewsView: This component is a page component. It displays the full details of a news post. It is the news page where users will read a piece of particular news. This will be rendered when the route /newspost/:id is navigated to.
- AddNewsDialog: This is a dialogue component. It is where news is added to our app.
Go to the GitHub repo, clone it and run one of the commands below to install all the dependencies.
npm install
or
yarn installStart the server:
npm start
or
yarn startGo to your browser and navigate to localhost:3000. From the starter file, our news application has two routes(pages):
- /news(NewsList): This route will render all the news in our app.
- /newspost/:id (NewsView): This route will render a particular news post. The id will be the id of the news post.
Getting started with Pagination
Now that we have our React app ready, we can implement pagination in our application. Strapi supports two kinds of pagination.
Pagination by page
This type of pagination divides the results into sections. It takes two arguments, page and pageSize. The argument pageSize specifies the number of results a page can contain while another argument, page, defines the page of results.
For instance, we have 100news. When we set the pageSize to 5 and the page argument to 2. It will split the 100news into 20 pages and display the 2nd page.
Let's see how it works in our react project.
Open the index.js file in the NewsListPage folder and add the following lines of code.
//Path: newsapp-gpl/newsapp-strapi/src/pages/NewsListPage/index.js
//...
export default function NewsList() {
//...
const [pageSize] = useState(2)//Setting the pageSize
const [page, setPage] = useState(1)//Creating the page argument
useEffect(() => {
async function fetchData() {
const {
data
} = await axios.post('http://localhost:1337/graphql', {
query: `
query GetNewsPost{
newsPosts(pagination: {page: ${page}, pageSize: ${pageSize}}){
data{
id
attributes{
title
writtenBy
image
createdAt
body
}
}
meta{
pagination{
total
pageCount
}
}
}
}
`,
});
setPageDetails(data?.data?.newsPosts?.meta?.pagination); //Storing the total pages
setNewsList(data?.data?.newsPosts?.data); //Storing the news post
}
fetchData();
}, [start]);
//...
}Three dots,
..., represents missing lines of code
Above, we created a function to handle the fetching of our paginated newsPosts from Strapi's graphql API. In the function, we specified the current page and pageSize then we passed these variables to the query and got our paginated newsPost.
Once we get a successful response, we store the metadata and the news post in the pageDetails and newsList state variables, respectively.
Now that we've got our news post let's handle the prev and next buttons. These buttons will help us to fetch the previous or next page.
Still, in the NewsListPage folder, add the following to the index.js file.
//Path: newsapp-gpl/newsapp-strapi/src/pages/NewsListPage/index.js
// ...
export default function NewsList() {
//...
const [page, setPage] = useState(1); //Creating the page argument
//...
function nextPage() {
setStart(pageSize + start);
setPage(page + 1);//Setting the value of the next page
}
function prevPage() {
setStart(start - pageSize);
setPage(page - 1);//Setting the value of the previous page
}
//...
}From the above lines of code, we increased the value of the page variable when we click on the Next button. Doing this will fetch the results for the next page and vice versa for the Prev button.
Pagination by offset
Now, we will learn the offset method of paginating our results.
Open the index.js file in the NewsListOffset folder and add the following lines of code.
//Path: newsapp-gpl/newsapp-strapi/src/pages/NewsListOffset/index.js
//...
export default function NewsList() {
//...
const [limit] = useState(2)//Setting the pageSize
const [startOffset, setStartOffset] = useState(0);//Setting the start index for our request
useEffect(() => {
async function fetchData() {
const { data } = await axios.post('http://localhost:1337/graphql', {
query: `
query GetNewsPost{
newsPosts(pagination: {start: ${start}, limit: ${limit}}){
data{
id
attributes{
title
writtenBy
image
createdAt
body
}
}
meta{
pagination{
total
pageCount
}
}
}
}
`,
});
setPageDetails(data?.data?.newsPosts?.meta?.pagination);
setNewsList(data?.data?.newsPosts?.data);
}
fetchData();
}, [start, limit, page]);
//...
}In the above, we set the position of the first value to be retrieved using the startOffset variable and specified the maximum number of results using the limit variable. Then we stored the metadata and the news post in the pageDetails and newsList state variables, respectively.
How it works
We specified the index position of our first value to be 0 meaning, it will get the result at index position 0. Then we specified the maximum number of results to be got as 2. Doing this will retrieve the first and second results from the content model in Strapi.
Next, import the NewsListOffset/index.js into our App.js file
//Path: newsapp-gpl/newsapp-strapi/src/App.js
//...
// import NewsList from './pages/NewsListPage';
import NewsList from './pages/NewListOffset';//Replacing the Page pagination with the Offset paginationNow, let's add the Next and Prev functionality.
//Path: newsapp-gpl/newsapp-strapi/src/pages/NewsListOffset/index.js
//...
export default function NewsList() {
//...
const [startOffset, setStartOffset] = useState(0);//Setting the start index for our request
//...
function nextPage() {
setStart(limit + start);
setStartOffset(startOffset + limit);
}
function prevPage() {
setStart(start - limit);
setStartOffset(startOffset - limit);
}
//...
}Above, we added the maximum result count to our current first index value when the Next button is clicked. Doing this, we will get the next two results from Strapi, using the outcome from the sum as the starting index value.
Making a POST request
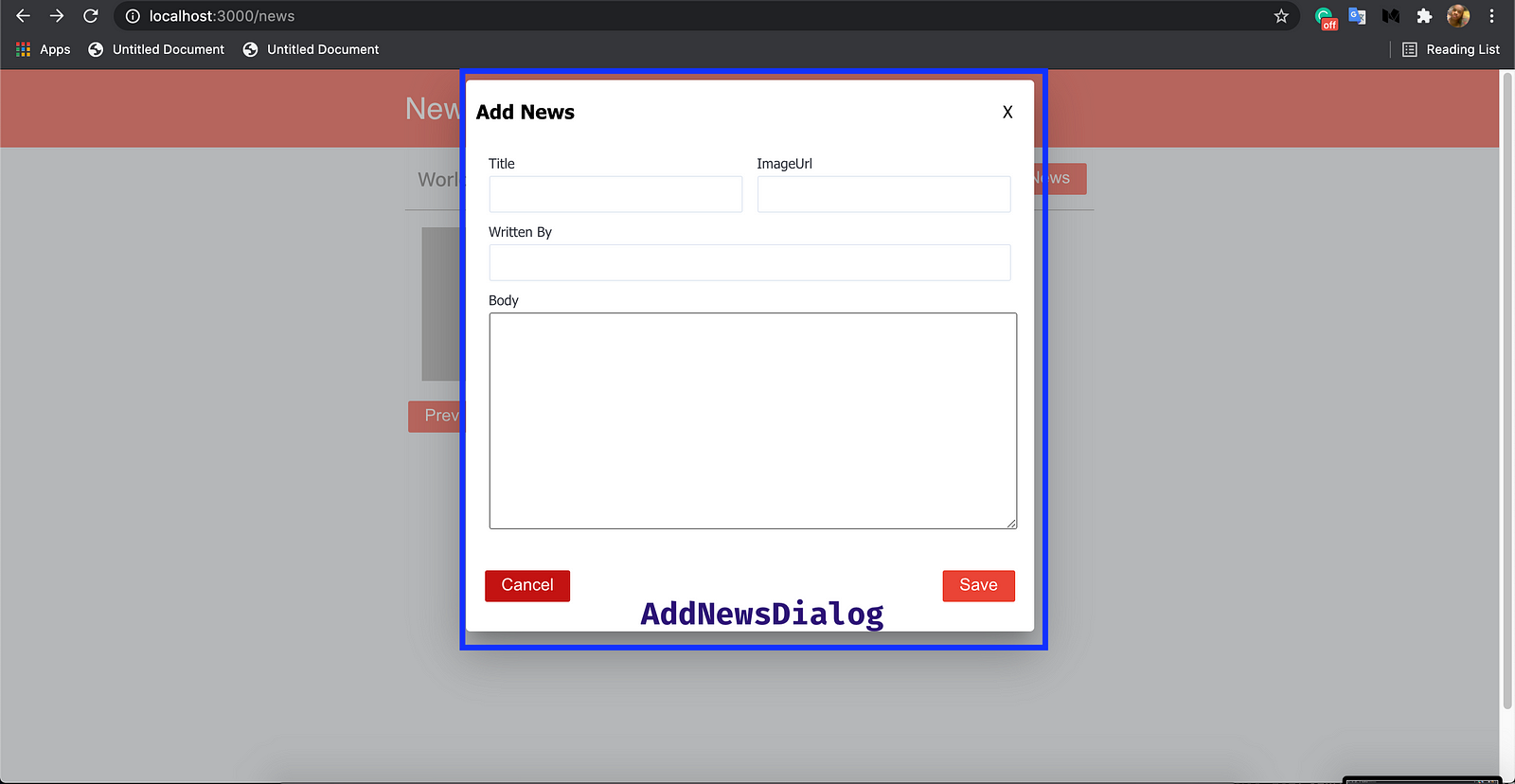
In our News app, users can create a news posts in the application. To create this functionality, we will get the news data from the user and send a POST request to Strapi's graphql API using the data. The user will provide this data using the modal provided when the user clicks on Add News.
//Path: newsapp-gpl/newsapp-strapi/src/components/AddNewsDialog/index.js
import { useState } from 'react';
import axios from 'axios';
export default function AddNewsDialog({ closeModal }) {
//...
async function saveNews() {
const title = window.newsTitle.value;
const imageUrl = window.newsImageUrl.value;
const writtenBy = window.newsWrittenBy.value;
const body = window.newsBody.value;
if (title && imageUrl && writtenBy && body) {
const data = await axios.post('http://localhost:1337/graphql', {
query: `
mutation CreateNewsPost{
createNewsPost(data: {title: "${title}",image: "${imageUrl}", body: "${body}", writtenBy: "${writtenBy}"}){
data{
id
attributes{
title
image
writtenBy
body
}
}
}
}
`,
});
console.log(data);
} else {
alert('Fill up the fields');
}
}
//...
}By Default, Strapi enables the draftAndPublish option which prevents data from being published using a POST request. This means that all data will be saved as draft and demands that the admin user manually publishes the data. We don't need this feature for this application.
To change this, open the schema.json file in the newsapp-gpl\newsapp-gpl-api\src\api\news-post\content-types\news-post folder and change the draftAndPublish option to false.
//Path: newsapp-gpl/newsapp-gpl-api/src/api/news-post/content-types/news-post/schema.json
{
//...
"options": {
"draftAndPublish": false
},
//...
}Displaying individual news
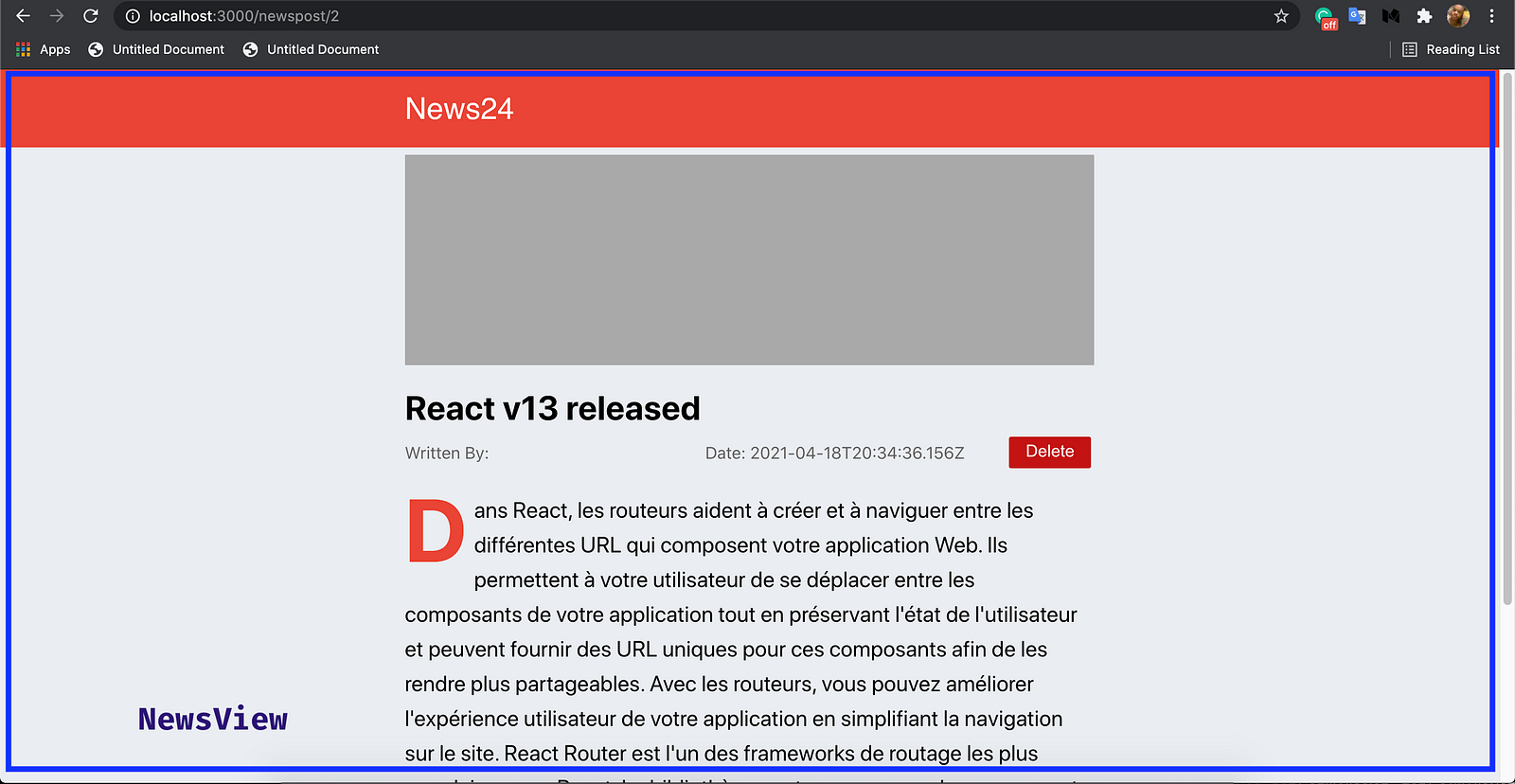
Here, we will display the news that the user clicks on. Once the user clicks on the news, we will get the id and make a GET request to Strapi using the news' id.
We can do this by adding the following lines of code to the index.js file in the NewsView folder.
//Path: newsapp-gpl/newsapp-strapi/src/pages/NewsView/index.js
//...
import { useParams } from 'react-router-dom';
export default function NewsView() {
let { id } = useParams();
useEffect(() => {
async function getNews() {
const data = await axios.post('http://localhost:1337/graphql', {
query: `
query{
newsPost(id: ${id}) {
data{
id
attributes{
title
body
image
writtenBy
createdAt
}
}
}
}
`,
});
setNews(data?.data?.newsPost?.data?.attributes);
}
getNews();
}, []);
//...
}We got the id from the URL using the react-router-dom package in the code above. Once we get the id we used it to fetch the news post for that particular news. When we get the fetched we stored the data in the news state variable.
Now, we will put display the news post.
//Path: newsapp-gpl/newsapp-strapi/src/pages/NewsView/index.js
//...
export default function NewsView() {
//...
return (
<div className="newsview">
<div style={{ display: 'flex' }}>
<a className="backHome" href="/news">
Back
</a>
</div>
<div
className="newsviewimg"
style={{ backgroundImage: `url(${news?.image})` }}
></div>
<div>
<div className="newsviewtitlesection">
<div className="newsviewtitle">
<h1>{news?.title}</h1>
</div>
<div className="newsviewdetails">
<span style={{ flex: '1', color: 'rgb(99 98 98)' }}>
Written By: <span>{news?.writtenBy}</span>
</span>
<span style={{ flex: '1', color: 'rgb(99 98 98)' }}>
Date:{' '}
<span>
{new Date(news?.createdAt).toLocaleDateString(
'en-us',
{
weekday: 'long',
year: 'numeric',
month: 'short',
day: 'numeric',
}
)}
</span>
</span>
<span>
<button className="btn-danger" onClick={deleteNews}>
Delete
</button>
</span>
</div>
</div>
<div className="newsviewbody">{news?.body}</div>
</div>
</div>
)
}You can test it out by clicking on the news on the Homepage. You should get similar output to the one shown below.

Deleting a News
We can view a particular news post; let's add a delete functionality to the news application.
We will use the id got from the URL to delete the news post from Strapi and then redirect the user back to the homepage.
//Path: newsapp-gpl/newsapp-strapi/src/pages/NewsView/index.js
//...
export default function NewsView() {
//...
async function deleteNews() {
if (window.confirm('Do you want to delete this news?')) {
await axios.post('http://localhost:1337/graphql', {
query: `
mutation{
deleteNewsPost(id: ${id}){
data{
attributes{
title
}
}
}
}`,
});
window.history.pushState(null, '', '/news');
window.location.reload();
}
}
//...
}Test
Load the app on localhost:3000. Then, press the Next and Prev buttons to navigate the pages.
Source code
Find the source code of this project below:
Conclusion
First, we learned what Strapi is, and then next, it was GraphQL and pagination. We demonstrated how to add pagination to our Strapi GraphQL endpoint by building a news app. In the news app, we used the next-prev type of UX pagination to demo pagination.
There are more UX pagination types:
- load more
- infinite scroll
I urge you to implement these to learn more about both paginations in the back-end and UX.




