
You're building an AI application that searches documents by meaning, not keywords—or implementing RAG where your LLM needs contextual information. Traditional databases weren't designed for semantic similarity search in high-dimensional vector spaces.
Vector databases solve this by storing embeddings and performing approximate nearest neighbor searches at scale. Whether you're building semantic search for a content management system, implementing a chatbot with contextual awareness, or creating recommendation engines, your database choice impacts performance, costs, and development velocity.
This guide evaluates Pinecone, Weaviate, Milvus, Qdrant, ChromaDB, and Pgvector with verified benchmarks, code examples, and integration patterns for Strapi headless CMS.
In brief
- Pinecone offers the fastest documented throughput, achieving 74,000 QPS at 90% recall during the BigANN 2023 competition for filtered search workloads (10M vectors, 192 dimensions), though benchmark results show P50 ~45ms and P99 ~96ms latency sustained at 600 QPS with 135M vectors; managed-only deployment eliminates self-hosted options.
- Weaviate provides the lowest documented query latency at 2.8ms mean response time (P99: 4.4ms) with flexible deployment across managed cloud and self-hosted environments, tested on the DBPedia OpenAI dataset.
- Milvus supports the most indexing algorithms, including GPU acceleration, and handles unlimited entities per collection for maximum scale.
- Self-hosted solutions like Qdrant and ChromaDB eliminate licensing costs but require Kubernetes expertise and 20-40 hours of infrastructure learning investment.
1. Pinecone
Pinecone runs entirely as a managed service, which means you're trading infrastructure control for zero operational overhead. The platform uses proprietary ANN algorithms and handles all scaling automatically across AWS, GCP, and Azure.
Pinecone achieved 74,000 QPS at 90% recall during the BigANN 2023 competition using the YFCC-10M dataset under filtered search conditions. For typical workloads, Pinecone demonstrates P50 latency around 45ms and P99 latency around 96ms at sustained 600 QPS with 135M vectors.
The current Python SDK (v5.4.1) and Node.js SDK (v4.1.0) released in January 2025 provide APIs for integration. Pinecone's December 2024 release notes show the Python SDK v5.4.0 introduced configurable connection pooling for improved performance.
Pinecone's serverless architecture automatically scales based on demand without manual cluster management, making it effective for applications with variable traffic patterns, though v5.4.1 signaled a strategic transition toward serverless with deprecation warnings for pod-based index creation.
Strengths
- Zero infrastructure management with automatic scaling and maintenance handled entirely by Pinecone.
- Highest verified throughput at 74,000 QPS achieved in BigANN 2023 competition testing on the YFCC-10M dataset with filtered search.
- Sub-minute deployment time via API-based setup without Kubernetes knowledge.
- Latency of P50 ~45ms and P99 ~96ms at 600 QPS with 135 million vectors.
- Built-in features including Assistant (RAG-as-a-Service) and Inference API for native embedding generation.
Weaknesses
- No self-hosted deployment option available, requiring acceptance of managed-only architecture.
- Consumption-based pricing model with storage costs of $0.33/GB per month, read operations at $16-24 per million, and write operations at $4-6 per million can become expensive at scale.
- Proprietary algorithms prevent optimization or customization compared to open-source alternatives.
- Once you've committed to Pinecone's API patterns, migrating to self-hosted alternatives means rewriting your vector operations layer.
Use Cases
Consider Pinecone when your team prioritizes rapid deployment and minimal operational overhead. The platform excels for startups and small teams without dedicated DevOps resources who need vector search immediately.
Pinecone works well for API-driven applications where managed infrastructure aligns with existing architecture patterns, and for prototypes that need to validate AI features before committing to self-hosted infrastructure investments.
2. Weaviate
Weaviate gives you deployment flexibility—start with their managed cloud, then move to self-hosted when you need it. It's open-source and supports HNSW, Flat, and Dynamic indexing algorithms.
Weaviate's benchmarks show the platform achieved low query latency with mean response times of 2.8ms and P99 latency of 4.4ms on one million vectors using a 30-core machine. Version 1.35 released in December 2025 introduced enhanced BM25 capabilities for hybrid search and named vectors support, allowing multiple vector spaces per object for multi-modal content applications.
Weaviate's architecture supports up to one trillion objects per collection with automatic vectorization through integrated embedding providers including OpenAI, Cohere, and Hugging Face. The platform offers flexible deployment through managed Weaviate Cloud, serverless instances, or self-hosted installations with SDKs for Python, JavaScript/TypeScript, Go, Java, and C#.
Strengths
- Lowest verified query latency at 2.8ms mean response time in official benchmarks with full methodology on 1M vectors.
- Flexible deployment options spanning managed cloud, serverless, and self-hosted environments.
- Automatic vectorization eliminating manual embedding generation code for rapid development.
- Native hybrid search combining vector similarity with BM25 keyword matching.
- Scale to one trillion objects per collection for enterprise-grade requirements.
Weaknesses
- HNSW algorithms may require higher memory consumption than traditional IVF approaches in standard implementations, though disk-based variants reduce this overhead.
- Most teams learn optimal HNSW parameters through trial and error—expect to run benchmark suites against your actual data before settling on settings.
- Configuration of vector databases requires expertise in algorithm selection, indexing parameters, and embedding model tuning for optimal performance.
Use Cases
Teams needing documented low-latency performance with deployment flexibility will find Weaviate's 2.8ms mean latency compelling for content-driven applications with semantic search across large document collections.
You can start with managed cloud for rapid prototyping, then migrate to self-hosted infrastructure as requirements evolve. The platform also supports multilingual content platforms where automatic vectorization with multilingual embedding models accelerates development, with deployment options including managed cloud, serverless, or self-hosted configurations to match your infrastructure requirements as they evolve.
3. Milvus
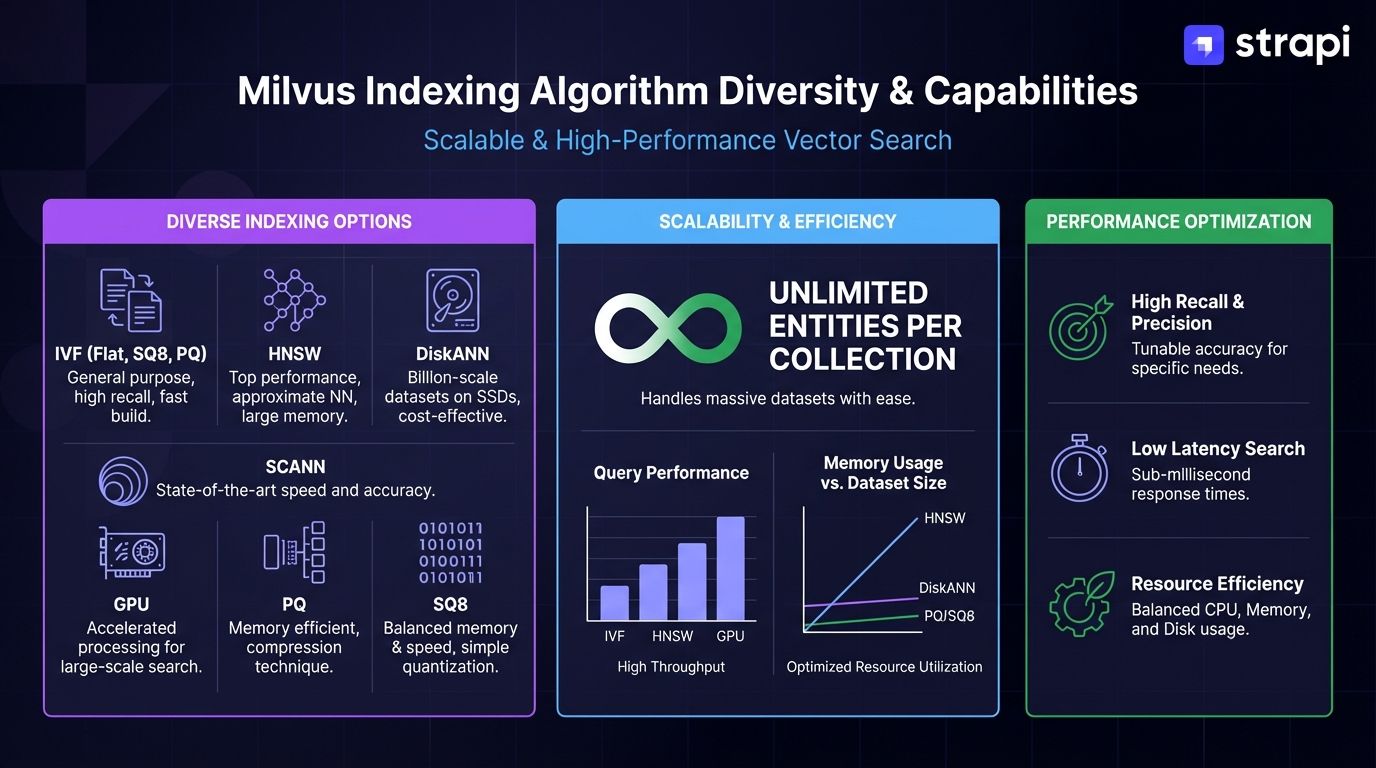 Milvus supports more indexing algorithms than any other platform we tested—IVF, HNSW, DiskANN, SCANN, GPU indexes, PQ, and SQ8 quantization. The v2.5.x series introduced native sparse vector support for sparse embeddings, GPU index acceleration, and multi-vector search across multiple vector fields simultaneously.
Milvus supports more indexing algorithms than any other platform we tested—IVF, HNSW, DiskANN, SCANN, GPU indexes, PQ, and SQ8 quantization. The v2.5.x series introduced native sparse vector support for sparse embeddings, GPU index acceleration, and multi-vector search across multiple vector fields simultaneously.
The v2.4.x LTS branch provides disk-based HNSW indexing that reduces memory requirements and MMap support for cost-efficient large-scale deployments.
Milvus architecture scales from lightweight Milvus Lite (a Python library for development and testing) through standalone Docker instances to distributed Kubernetes clusters handling unlimited entities per collection. Vendor benchmarks claim 2-5x faster performance than competitors, though these represent vendor claims requiring validation against your specific workload patterns.
Strengths
- Most algorithm support including GPU acceleration for compute-intensive workloads (IVF, HNSW, DiskANN, SCANN, GPU, PQ, SQ8).
- Unlimited entities per collection removing artificial scale constraints.
- Three deployment modes (Lite, Standalone, Distributed) spanning development through massive scale.
- Disk-based HNSW in v2.4.x LTS reduces memory footprint for cost optimization.
- Active development with both cutting-edge features (v2.5.x) and stable LTS branches (v2.4.x).
Weaknesses
- Self-hosted deployments require Kubernetes expertise for distributed systems, increasing operational complexity for teams lacking dedicated DevOps resources. If you've spent weekends debugging pod networking issues, you know this isn't trivial infrastructure.
- Configuration and parameter tuning complexity varies by platform: Milvus requires algorithm selection (IVF, HNSW, DiskANN, SCANN, GPU, PQ, SQ8) with performance testing, while Qdrant's HNSW tuning demands careful
ef_constructionandMparameter optimization. - Independent verification of vendor performance claims is limited: while ANN-Benchmarks provides standardized testing for Weaviate, Milvus, and Qdrant, Pinecone and ChromaDB require separate evaluation, making direct cross-database comparison under identical conditions unavailable.
Use Cases
Your team needs maximum algorithmic flexibility and massive-scale capabilities if you're building data-intensive applications where algorithm selection impacts performance. The platform benefits teams with strong infrastructure engineering capabilities who can leverage advanced features like partition keys and dynamic schemas (available in v2.4.x LTS and later) for multi-tenant architectures.
For applications requiring unlimited scalability, Milvus supports unlimited entities per collection and offers both open-source self-hosted and managed Zilliz Cloud deployment options. Your API-first application needs specialized indexing strategies like GPU acceleration for real-time similarity search on enormous datasets.
4. Qdrant
Qdrant combines HNSW (Hierarchical Navigable Small World) indexing with a custom Gridstore key-value backend, optimized for billion-scale datasets with emphasis on query speed and throughput.
Version 1.16.x introduced Colbert support for multi-vector retrieval, binary quantization achieving 32x memory reduction with minimal accuracy loss, and built-in inference capabilities for native embedding generation. The platform provides managed cloud services with a free tier, self-hosted deployments, and hybrid cloud options.
Qdrant's Rust-based implementation prioritizes low latency and high throughput. The platform offers SDKs for Python, JavaScript/TypeScript, Go, Java, .NET, and Rust.
Strengths
- Binary quantization delivers 32x memory reduction enabling larger datasets on constrained infrastructure.
- Built-in inference eliminates external embedding API dependencies for simplified architecture.
- Free tier available for evaluation and small workloads.
- Rust implementation provides memory safety and performance characteristics.
- Active community with frequent releases and responsive GitHub maintenance.
Weaknesses
- Performance claims require independent validation, as specific latency numbers lack detailed methodology (compared to Weaviate's documented P50: 2.8ms, P99: 4.4ms on standardized benchmarks).
- Limited ecosystem compared to platforms with more marketplace integrations.
- Cloud feature development continues to evolve across platforms.
Use Cases
Memory efficiency matters most for teams with infrastructure cost constraints, and Qdrant's binary quantization delivering 32x memory reduction makes it practical for recommendation systems where accuracy trade-offs are acceptable.
You'll find Qdrant effective for real-time applications where Rust's performance characteristics align with latency requirements. The free tier makes Qdrant attractive for developer experience during prototyping and proof-of-concept validation before committing to paid infrastructure.
5. ChromaDB
ChromaDB provides a developer-friendly vector database with intelligent tiering architecture featuring hot memory cache and warm SSD cache layers. Version 0.5.x evolved from embedded-only deployment to client-server architecture supporting workloads, with multi-modal capabilities spanning text, image, and audio embeddings.
The platform scales to five million records per collection with one million collections per database, targeting small-to-medium deployments and rapid development workflows. Performance is cache-sensitive:
P50 latency reaches approximately 20ms with warm cache but extends to 650ms with cold cache on 100K vector datasets. This is where cold cache comes back to haunt you—that initial query after a restart will feel slow.
Performance exhibits cache sensitivity, which is a key architectural trade-off in ChromaDB's design. With 100K vectors at 384 dimensions, the database achieves P50 latency of 20ms in warm cache versus 650ms in cold cache, representing a 32.5x performance differential.
This cache-sensitive behavior reflects ChromaDB's HNSW fork implementation, which prioritizes simplicity and ease of use over maximum throughput—a design choice that aligns with the platform's focus on rapid prototyping and development environments rather than large-scale deployments.
Strengths
- Fastest initial setup with minimal configuration requirements for rapid prototyping.
- Multi-modal support handling diverse data types (text, images, sparse vectors) without separate specialized databases.
- Development actively advancing toward v1.0 stable release with strong community engagement.
- Zero-dependency embedded modes for edge deployments and development environments.
- Client-server architecture enabling deployments beyond embedded-only limitations.
Weaknesses
- Cache-sensitive performance creates 32.5x latency variation between warm and cold cache states, requiring careful cache management strategies.
- Five million record per collection limit constrains very large-scale applications.
- Younger platform with smaller deployment base compared to established alternatives.
Use Cases
Development velocity wins over maximum scale in many scenarios. ChromaDB's minimal configuration requirements accelerate proof-of-concept AI features in headless CMS platforms, while embedded deployment modes simplify local iteration during plugin development.
When paired with content management systems through integration patterns documented in implementations, multi-modal capabilities work well for AI-powered content discovery, handling images, audio, and text within unified semantic search interfaces.
6. Pgvector
Pgvector extends PostgreSQL with vector similarity search through IVFFlat and HNSW indexing algorithms, integrating directly into PostgreSQL 13+ instances. Version 0.8.1 released in October 2024 supports up to 16,000 dimensions with standard ACID transaction guarantees.
Unlike standalone vector databases, pgvector eliminates separate infrastructure management by leveraging existing PostgreSQL deployments across self-hosted installations or managed services including AWS RDS, Google Cloud SQL, Azure Database, and Railway.
The extension enables vector similarity search within PostgreSQL's standard query planning system, allowing combination of vector similarity search with traditional relational queries in single transactions.
Pgvector inherits PostgreSQL's operational characteristics including backup procedures, replication topology, and monitoring infrastructure, operating as a native extension that supports IVFFlat and HNSW indexing algorithms.
Strengths
- Zero additional infrastructure for teams already operating PostgreSQL reducing operational complexity.
- ACID transactions enable atomic operations combining vector search with relational updates.
- Mature PostgreSQL operational tools apply directly (pg_dump, pg_restore, streaming replication).
- Available across all major PostgreSQL providers eliminating vendor lock-in.
- SQL interface leverages existing database skills without learning specialized query languages.
Weaknesses
- Performance limitations compared to specialized vector databases at massive scale.
- No official performance benchmarks available for validation against specialized alternatives.
- Limited algorithm selection compared to platforms like Milvus.
Use Cases
PostgreSQL teams already managing relational data can add vector search without introducing separate infrastructure. This approach reduces operational complexity for content management systems requiring semantic search alongside traditional database operations.
The approach benefits teams without dedicated infrastructure resources who can leverage existing PostgreSQL expertise, and your customizable infrastructure already standardizes on PostgreSQL deployments.
Integrating Vector Databases with Strapi
Full-stack developers can implement vector search for Strapi CMS applications through several validated architectural patterns. The Upstash Search plugin listed in the Strapi Marketplace provides immediate AI-powered semantic search with automatic content synchronization requiring minimal configuration.
Lifecycle hooks enable lightweight integration without plugin complexity, automatically indexing content to vector databases on create, update, or delete events. For RAG applications, developers can integrate Strapi content with vector databases through custom plugins, external middleware services for complete architectural separation, or community-contributed solutions documented on GitHub.
These integrations transform static content repositories into intelligent systems supporting semantic content discovery, context-aware responses, and personalized content recommendations grounded in your actual CMS data.
Whether you choose marketplace plugins for rapid deployment, custom lifecycle hooks for real-time sync, or external middleware for architectural separation, pairing the right vector database with Strapi's flexible content architecture transforms your CMS into an AI-powered platform capable of semantic search, contextual chatbots, and intelligent recommendations. Start with the code examples here, validate against your workload, and scale from there.



