

Introduction
Imagine if your search could think. When users type "remote work best practices," they'd instantly find your article titled "Telecommeting Strategies for Modern Teams" because the search understands the conceptual relationship between these phrases.
This is semantic search in action: technology that comprehends meaning rather than just matching keywords.
In this guide, you'll build a Strapi 5 plugin that brings semantic search to your content.
The system automatically generates AI embeddings when content is created and provides lightning-fast search through clean REST APIs. You'll finish with a production-ready plugin that transforms how users discover your content, complete with configurable field mapping.
Prerequisites
Before we dive in, you'll need:
- Strapi 5 project (we'll use the latest stable version)
- OpenAI API key with access to the embeddings endpoint
- Node.js 18+ and npm
- Basic JavaScript/TypeScript knowledge
- Understanding of Strapi 5 plugins development (helpful but not required)
We'll be working with OpenAI's text-embedding-ada-002 model, which generates 1536-dimensional vectors from text. Each embedding costs about $0.0001 per 1000 tokens, making this economical even for large content libraries.
Step 1: Scaffolding Your Strapi Semantic Search Plugin
Let's start by creating our plugin structure. We'll build this from scratch to understand every component.
1. Create Plugin Directory Structure
Ensure you CD in to your Strapi project folder. Then create the plugin directory structure:
mkdir -p src/plugins/semantic-search/server/src/{controllers,services,routes}
cd src/plugins/semantic-searchNext, set up the plugin's package.json:
// Path: ./src/plugins/semantic-search
{
"name": "strapi-plugin-semantic-search",
"version": "1.1.0",
"description": "Intelligent semantic search plugin for Strapi 5 powered by OpenAI embeddings",
"main": "strapi-server.js",
"keywords": [
"strapi",
"plugin",
"semantic-search",
"search",
"embedding",
"openai",
"ai"
],
"dependencies": {
"axios": "^1.10.0",
"openai": "^5.8.2"
},
"engines": {
"node": ">=18.0.0 <=22.x.x"
},
"strapi": {
"displayName": "Semantic Search",
"name": "semantic-search",
"description": "Add semantic search capabilities to your Strapi content using OpenAI embeddings",
"kind": "plugin"
}
}2. Install the dependencies:
npm install3. Create Plugin Entry Point
Create the plugin entry point (src/plugins/semantic-search/strapi-server.js) and add the following code:
// Path: ./src/plugins/semantic-search/strapi-server.js
module.exports = require("./server");This file instructs Strapi on where to locate our server-side plugin code. Every Strapi plugin needs this entry point.
4. Enable Plugin in Strapi
Now enable the plugin in your main Strapi configuration (config/plugins.js):
// ./config/plugins.js
module.exports = ({ env }) => ({
"semantic-search": {
enabled: true,
resolve: "./src/plugins/semantic-search",
},
});5. Add OpenAI API key
Add your OpenAI API key to your .env file:
OPENAI_API_KEY=your_openai_api_key_hereStep 2: Create Embedding and Vector Services for OpenAI Semantic Search
The heart of our plugin lies in three interconnected services. Think of them as specialized workers: one talks to OpenAI, another handles vector math, and the third orchestrates search operations.
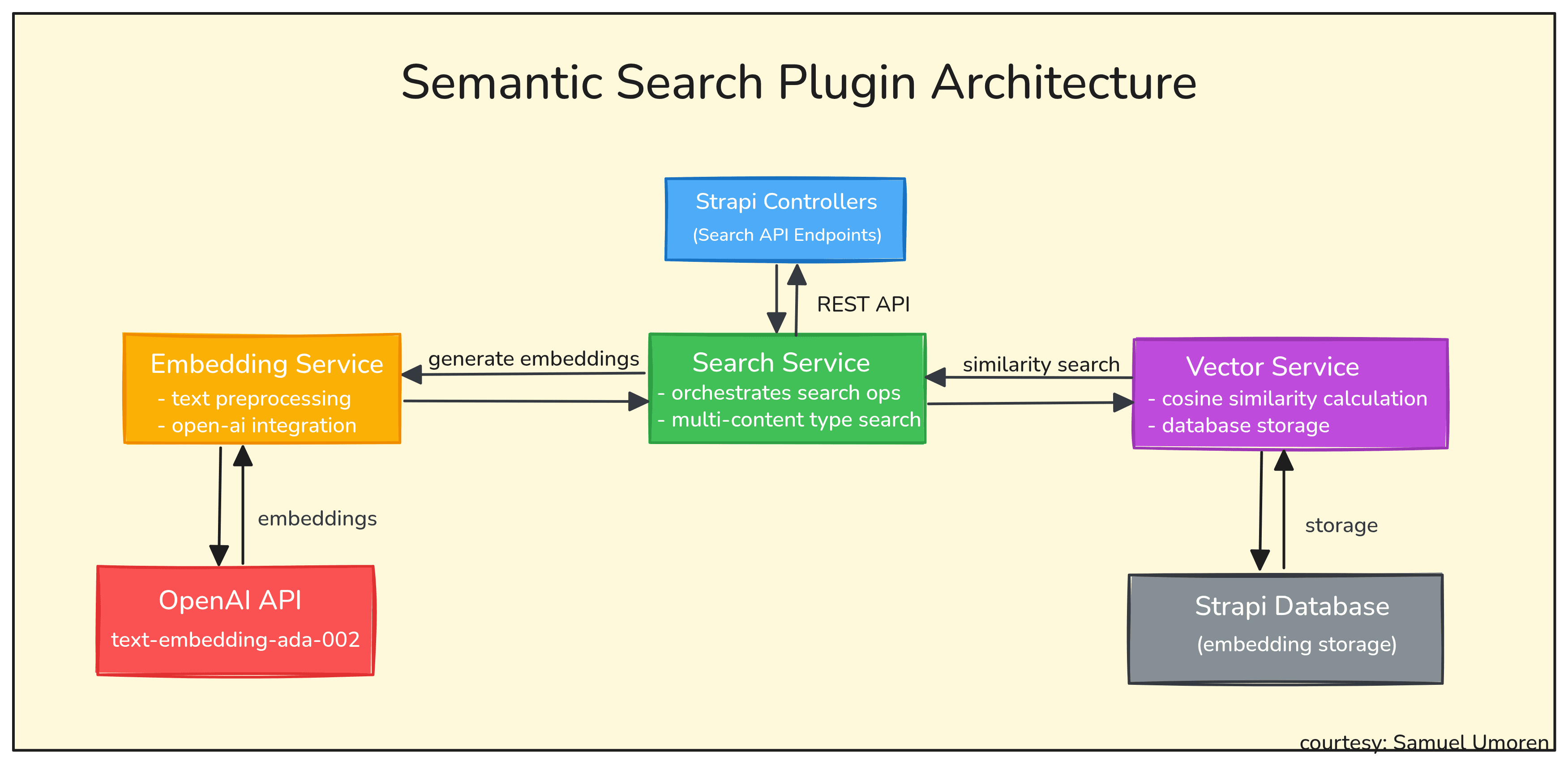
1. Create Index File for Services
Create the services index file (server/src/services/index.js):
// Path: ./src/plugins/semantic-search/server/src/services/index.js
"use strict";
const embeddingService = require("./embedding-service");
const vectorService = require("./vector-service");
const searchService = require("./search-service");
module.exports = {
embeddingService,
vectorService,
searchService,
};2. Create Embedding Service: OpenAI Integration
This service handles all OpenAI communication and text preprocessing. We'll build it in three parts within the same server/src/services/embedding-service.js file: initialization, text preprocessing, and embedding generation.
Service Initialization
First, set up the OpenAI client and validate the API key. Create ./src/plugins/semantic-search/server/src/services/embedding-service.js and start with the initialization code:
// Path: ./src/plugins/semantic-search/server/src/services/embedding-service.js
'use strict';
const { OpenAI } = require('openai');
module.exports = ({ strapi }) => ({
init() {
if (!process.env.OPENAI_API_KEY) {
throw new Error('OPENAI_API_KEY environment variable is required');
}
this.openai = new OpenAI({
apiKey: process.env.OPENAI_API_KEY,
});
strapi.log.info('OpenAI embedding service initialized');
},The initialization validates that your API key exists and creates the OpenAI client that we'll use for all embedding requests.
Text Preprocessing
Add the preprocessing function to the same embedding-service.js file:
// Path: ./src/plugins/semantic-search/server/src/services/embedding-service.js
// ...
preprocessText(text) {
if (!text) return '';
// Remove HTML tags and normalize whitespace
const cleaned = text
.replace(/<[^>]*>/g, ' ') // Remove HTML tags
.replace(/\\s+/g, ' ') // Normalize whitespace
.trim();
// Limit to 8000 characters for safety (well under OpenAI's token limit)
return cleaned.substring(0, 8000);
},This preprocessing removes HTML tags from rich text fields and normalizes whitespace. The 8000-character limit provides a safety buffer well under OpenAI's token limits.
Embedding Generation
Finally, add the core embedding generation function to complete the embedding-service.js file:
// Path: ./src/plugins/semantic-search/server/src/services/embedding-service.js
// ...
async generateEmbedding(text) {
if (!text || text.trim().length === 0) {
throw new Error('Text is required for embedding generation');
}
const processedText = this.preprocessText(text);
const originalLength = text.length;
const processedLength = processedText.length;
try {
const response = await this.openai.embeddings.create({
model: 'text-embedding-ada-002',
input: processedText,
});
const embedding = response.data[0].embedding;
strapi.log.debug(`Generated embedding: ${embedding.length} dimensions`);
return {
embedding,
processedText,
originalLength,
processedLength
};
} catch (error) {
strapi.log.error('OpenAI embedding generation failed:', error.message);
throw error;
}
}
});This function sends preprocessed text to OpenAI and returns both the 1536-dimensional embedding and metadata about the processing.
3. Create Vector Service: Mathematics and Storage
The vector service handles similarity calculations and database operations. We'll build three key functions within ./src/plugins/semantic-search/server/src/services/vector-service.js: similarity calculation, storage, and search.
Cosine Similarity Calculation
Start with the mathematical foundation of semantic search. Create ./src/plugins/semantic-search/server/src/services/vector-service.js:
// Path: ./src/plugins/semantic-search/server/src/services/vector-service.js
// ...
'use strict';
module.exports = ({ strapi }) => ({
calculateCosineSimilarity(vectorA, vectorB) {
if (!vectorA || !vectorB || vectorA.length !== vectorB.length) {
throw new Error('Invalid vectors for similarity calculation');
}
let dotProduct = 0;
let magnitudeA = 0;
let magnitudeB = 0;
for (let i = 0; i < vectorA.length; i++) {
dotProduct += vectorA[i] * vectorB[i];
magnitudeA += vectorA[i] * vectorA[i];
magnitudeB += vectorB[i] * vectorB[i];
}
magnitudeA = Math.sqrt(magnitudeA);
magnitudeB = Math.sqrt(magnitudeB);
if (magnitudeA === 0 || magnitudeB === 0) {
return 0;
}
return dotProduct / (magnitudeA * magnitudeB);
},Cosine similarity measures the angle between two vectors, focusing on direction rather than magnitude. This is like comparing where two people are pointing rather than how far their arms extend: direction matters, not distance.
A score of 1.0 means identical meaning, 0.0 means no relationship, and -1.0 means opposite concepts. For content discovery, you'll typically see scores between 0.3 (somewhat related) and 0.95 (highly similar but not identical).
Why cosine similarity for semantic search? Unlike Euclidean distance, cosine similarity ignores magnitude differences. Two articles about machine learning—one with 50 mentions of "AI" and another with 5 mentions—are conceptually similar despite different intensities. They point in the same direction in vector space.
4. Create Function to Store Embeddings: Embedding Storage
Add the function to store embeddings in your Strapi database to the same vector-service.js file:
// Path: ./src/plugins/semantic-search/server/src/services/vector-service.js
// ...
async storeEmbedding(documentId, embedding, contentType, metadata = {}) {
if (!documentId || !embedding || !contentType) {
throw new Error('Document ID, embedding, and content type are required');
}
try {
const updated = await strapi.documents(contentType).update({
documentId: documentId,
data: {
embedding: embedding,
embeddingMetadata: {
model: 'text-embedding-ada-002',
generatedAt: new Date().toISOString(),
dimensions: embedding.length,
...metadata
}
}
});
strapi.log.debug(`Stored embedding for ${contentType} document ${documentId}`);
return updated;
} catch (error) {
strapi.log.error(`Failed to store embedding for ${contentType} document ${documentId}:`, error.message);
throw error;
}
},This function saves both the embedding vector and helpful metadata like generation timestamp and model information.
5. Create Similarity Search Function
Finally, add the search function that finds similar content to complete the vector-service.js file:
// Path: ./src/plugins/semantic-search/server/src/services/vector-service.js
// ...
async searchSimilar(queryEmbedding, contentType, options = {}) {
const {
limit = 10,
threshold = 0.1,
filters = {},
locale = null
} = options;
try {
const documents = await strapi.documents(contentType).findMany({
filters: {
embedding: { $notNull: true },
...filters
},
locale: locale,
limit: 1000 // Fetch up to 1000 documents for similarity comparison
});
if (!documents || documents.length === 0) {
return [];
}
const scoredResults = documents
.map(doc => {
if (!doc.embedding) return null;
try {
const similarity = this.calculateCosineSimilarity(queryEmbedding, doc.embedding);
return {
...doc,
similarityScore: similarity
};
} catch (error) {
strapi.log.warn(`Failed to calculate similarity for document ${doc.documentId}:`, error.message);
return null;
}
})
.filter(result => result !== null && result.similarityScore >= threshold)
.sort((a, b) => b.similarityScore - a.similarityScore)
.slice(0, limit);
strapi.log.debug(`Found ${scoredResults.length} similar documents for ${contentType}`);
return scoredResults;
} catch (error) {
strapi.log.error(`Failed to search similar documents for ${contentType}:`, error.message);
throw error;
}
}
});This function fetches documents with embeddings, calculates similarity scores, filters by threshold, and returns the most relevant results sorted by score.
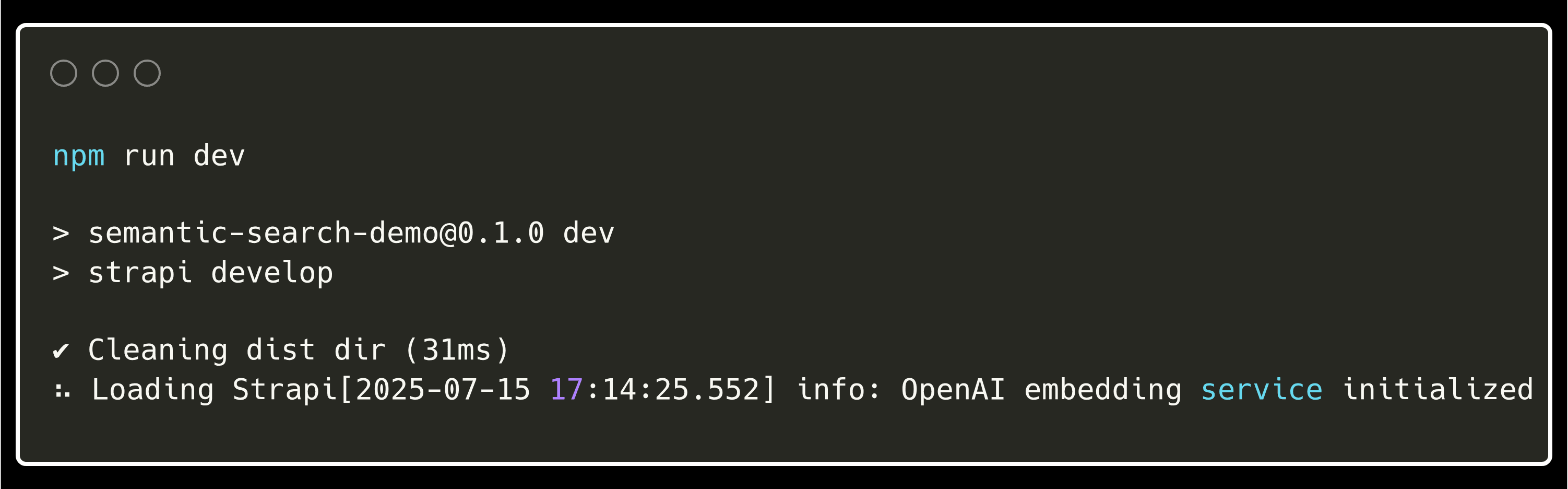
Strapi logs during startup, highlighting the embedding service initialization message.
6. Create Search Service: Orchestration
The search service ties everything together, coordinating between the embedding and vector services. We'll build two main functions: single content type search and multi-content type search.
Single Content Type Search
Start with the core search functionality. Create ./src/plugins/semantic-search/server/src/services/search-service.js:
// Path: ./src/plugins/semantic-search/server/src/services/search-service.js
'use strict';
module.exports = ({ strapi }) => ({
async semanticSearch(query, contentType, options = {}) {
if (!query || !contentType) {
throw new Error('Query and content type are required');
}
const startTime = Date.now();
try {
// Generate embedding for the search query
const embeddingService = strapi.plugin('semantic-search').service('embeddingService');
const queryEmbedding = await embeddingService.generateEmbedding(query);
// Search for similar documents
const vectorService = strapi.plugin('semantic-search').service('vectorService');
const results = await vectorService.searchSimilar(
queryEmbedding.embedding,
contentType,
options
);
const searchTime = Date.now() - startTime;
strapi.log.info(`Semantic search completed in ${searchTime}ms for query: "${query}"`);
return {
query,
contentType,
results,
metadata: {
totalResults: results.length,
queryProcessing: {
originalQuery: query,
processedText: queryEmbedding.processedText,
embeddingDimensions: queryEmbedding.embedding.length
},
searchOptions: {
limit: options.limit || 10,
threshold: options.threshold || 0.1,
locale: options.locale || null,
filtersApplied: Object.keys(options.filters || {}).length > 0
},
performance: {
searchTime: `${searchTime}ms`
}
}
};
} catch (error) {
strapi.log.error(`Semantic search failed for query "${query}":`, error.message);
throw error;
}
},This function starts by validating inputs and recording the start time for performance tracking. It then retrieves the embedding service from the plugin registry and converts the user's search query into a 1536-dimensional vector through OpenAI's API. With this query embedding in hand, it calls the vector service to find similar documents by calculating cosine similarity scores against all stored document embeddings in the specified content type.
The function wraps up by calculating the total search time and returning a comprehensive response object that includes the matching documents sorted by relevance, along with detailed metadata about query processing, search options applied, and performance metrics for monitoring and debugging purposes.
Multi-Content Type Search
Add the capability to search across multiple content types simultaneously:
// Path: ./src/plugins/semantic-search/server/src/services/search-service.js
// ...
async multiContentTypeSearch(query, contentTypes, options = {}) {
if (!query || !contentTypes || contentTypes.length === 0) {
throw new Error('Query and content types are required');
}
const { aggregateResults = true, ...searchOptions } = options;
try {
const searchPromises = contentTypes.map(contentType =>
this.semanticSearch(query, contentType, searchOptions)
);
const results = await Promise.all(searchPromises);
if (aggregateResults) {
// Combine and sort all results by similarity score
const allResults = results.flatMap(result =>
result.results.map(item => ({
...item,
sourceContentType: result.contentType
}))
);
allResults.sort((a, b) => b.similarityScore - a.similarityScore);
return {
query,
contentTypes,
results: allResults.slice(0, searchOptions.limit || 10),
metadata: {
totalResults: allResults.length,
searchedContentTypes: contentTypes.length
}
};
}
return {
query,
contentTypes,
results,
metadata: {
searchedContentTypes: contentTypes.length
}
};
} catch (error) {
strapi.log.error(`Multi-content type search failed for query "${query}":`, error.message);
throw error;
}
}
});This function performs parallel searches across multiple content types by creating an array of search promises that execute the single semantic search function for each content type concurrently.
When aggregateResults is true, it flattens all the individual search results into a single array, adds a sourceContentType field to track which content type each result came from, then sorts the entire collection by similarity score to create a unified ranking across all content types.
Step 3: Automate Semantic Embedding Generation in Strapi
This automation makes semantic search transparent to content creators. When they save content, the system automatically generates embeddings without any manual intervention.
1. Strapi Plugin Registration and Bootstrap
Start with the main plugin setup. Create server/src/index.js:
// Path: ./src/plugins/semantic-search/server/src/index.js
"use strict";
const services = require("./services");
const controllers = require("./controllers");
const routes = require("./routes");
module.exports = {
services,
controllers,
routes,
register({ strapi }) {
// Initialize the embedding service
const embeddingService = strapi
.plugin("semantic-search")
.service("embeddingService");
embeddingService.init();
},
bootstrap({ strapi }) {
strapi.log.info("Semantic Search plugin bootstrapped successfully");
// Register lifecycle hooks for auto-embedding
registerEmbeddingLifecycles(strapi);
},
};This plugin entry point follows Strapi's plugin lifecycle by exporting the required services, controllers, and routes, then defining two key phases of initialization.
2. Create Strapi Lifecycle Hook for Plugin
Add the function that registers automatic embedding generation for your content types:
// Path: ./src/plugins/semantic-search/server/src/index.js
// ...
function registerEmbeddingLifecycles(strapi) {
// Get configuration from plugin config
const config = strapi.config.get("plugin.semantic-search") || {};
// Default content types and field mappings
const defaultContentTypes = {
"api::article.article": ["title", "content", "summary"],
"api::blog.blog": ["title", "body", "excerpt"],
};
// Use configured content types or defaults
const contentTypes = validateConfiguration(
config.contentTypes || defaultContentTypes,
strapi
);
// Store the configuration for use in other functions
strapi.plugin("semantic-search").config = { contentTypes };
Object.keys(contentTypes).forEach((contentType) => {
// Use Strapi 5 lifecycle hooks
strapi.db.lifecycles.subscribe({
models: [contentType],
beforeCreate: async (event) => {
await processDocumentEmbedding(event, "create", strapi);
},
beforeUpdate: async (event) => {
await processDocumentEmbedding(event, "update", strapi);
},
});
strapi.log.info(
`Registered embedding lifecycle hooks for ${contentType} with fields: ${contentTypes[
contentType
].join(", ")}`
);
});
}This function registers hooks that automatically trigger embedding generation when content is created or updated.
3. Create Document Processing Function
Add the core function that processes documents and generates embeddings:
// Path: ./src/plugins/semantic-search/server/src/index.js
// ...
async function processDocumentEmbedding(event, action, strapi) {
const { model, params } = event;
const data = params.data;
// Get the model name as string
const modelName = typeof model === "string" ? model : model.uid;
// Skip admin and plugin content types
if (modelName.startsWith("admin::") || modelName.startsWith("plugin::")) {
return;
}
try {
const embeddingService = strapi
.plugin("semantic-search")
.service("embeddingService");
// Extract text content from the document
const textContent = extractTextContent(data, modelName, strapi);
if (!textContent || textContent.trim().length < 10) {
strapi.log.debug(
`Skipping embedding generation for ${modelName} - insufficient text content`
);
return;
}
// Generate embedding
const embeddingResult = await embeddingService.generateEmbedding(
textContent
);
if (embeddingResult && embeddingResult.embedding) {
// Add embedding to the data that will be saved
data.embedding = embeddingResult.embedding;
data.embeddingMetadata = {
model: "text-embedding-ada-002",
generatedAt: new Date().toISOString(),
dimensions: embeddingResult.embedding.length,
processedText: embeddingResult.processedText,
originalLength: embeddingResult.originalLength,
processedLength: embeddingResult.processedLength,
};
strapi.log.info(
`Generated embedding for ${modelName} document (${action})`
);
}
} catch (error) {
strapi.log.error(
`Failed to generate embedding for ${modelName} document:`,
error.message
);
// Don't throw error - we don't want to break content creation/update
}
}4. Create Text Extraction Function
Add the function that extracts searchable text from configured fields:
// Path: ./src/plugins/semantic-search/server/src/index.js
// ...
function extractTextContent(data, modelName, strapi) {
let textContent = "";
// Get configured field mappings for this content type
const config = strapi.plugin("semantic-search").config || {};
const contentTypes = config.contentTypes || {};
// Get fields for this specific content type, or use defaults
const textFields = contentTypes[modelName] || [
"title",
"name",
"content",
"body",
"summary",
"description",
"excerpt",
];
textFields.forEach((field) => {
if (data[field]) {
if (typeof data[field] === "string") {
textContent += data[field] + " ";
} else if (Array.isArray(data[field])) {
// Handle rich text blocks or arrays
textContent += JSON.stringify(data[field]) + " ";
} else if (typeof data[field] === "object") {
// Handle nested objects (like rich text)
textContent += JSON.stringify(data[field]) + " ";
}
}
});
return textContent.trim();
}5. Create Plugin Configuration Validation Function
Finally, add the validation function that ensures plugin configuration is correct:
// Path: ./src/plugins/semantic-search/server/src/index.js
// ...
function validateConfiguration(contentTypes, strapi) {
if (!contentTypes || typeof contentTypes !== "object") {
strapi.log.warn(
"Semantic Search: Invalid contentTypes configuration, using defaults"
);
return {
"api::article.article": ["title", "content", "summary"],
"api::blog.blog": ["title", "body", "excerpt"],
};
}
const validatedConfig = {};
Object.keys(contentTypes).forEach((contentType) => {
// Validate content type format
if (!contentType.startsWith("api::") || !contentType.includes(".")) {
strapi.log.warn(
`Semantic Search: Invalid content type format: ${contentType}. Should be like 'api::article.article'`
);
return;
}
// Validate fields array
const fields = contentTypes[contentType];
if (!Array.isArray(fields) || fields.length === 0) {
strapi.log.warn(
`Semantic Search: Invalid fields for ${contentType}. Should be an array of field names`
);
return;
}
// Validate field names
const validFields = fields.filter((field) => {
if (typeof field !== "string" || field.trim() === "") {
strapi.log.warn(
`Semantic Search: Invalid field name '${field}' for ${contentType}`
);
return false;
}
return true;
});
if (validFields.length > 0) {
validatedConfig[contentType] = validFields;
strapi.log.info(
`Semantic Search: Validated configuration for ${contentType}: ${validFields.join(
", "
)}`
);
}
});
return validatedConfig;
}Step 4: Build RESTful Semantic Search APIs in Strapi
Now we'll expose our semantic search capabilities through clean REST APIs.
1. Create Controller
Create the controller (./src/plugins/semantic-search/server/src/controllers/search-controller.js) and add the following code:
// Path: ./src/plugins/semantic-search/server/src/controllers/search-controller.js
// ...
"use strict";
module.exports = ({ strapi }) => ({
async search(ctx) {
try {
const {
query,
contentType,
limit = 10,
threshold = 0.1,
filters = {},
} = ctx.request.body;
// Validate required parameters
if (!query || !contentType) {
return ctx.badRequest("Query and contentType are required");
}
// Validate limits
if (limit > 50) {
return ctx.badRequest("Limit cannot exceed 50");
}
const searchService = strapi
.plugin("semantic-search")
.service("searchService");
const results = await searchService.semanticSearch(query, contentType, {
limit,
threshold,
filters,
locale: ctx.request.query.locale,
});
ctx.body = {
success: true,
data: results,
};
} catch (error) {
strapi.log.error("Search API error:", error.message);
ctx.badRequest(error.message);
}
},
async multiSearch(ctx) {
try {
const {
query,
contentTypes,
limit = 10,
threshold = 0.1,
aggregateResults = true,
} = ctx.request.body;
// Validate required parameters
if (!query || !contentTypes || !Array.isArray(contentTypes)) {
return ctx.badRequest("Query and contentTypes array are required");
}
if (contentTypes.length === 0) {
return ctx.badRequest("At least one content type is required");
}
const searchService = strapi
.plugin("semantic-search")
.service("searchService");
const results = await searchService.multiContentTypeSearch(
query,
contentTypes,
{
limit,
threshold,
aggregateResults,
locale: ctx.request.query.locale,
}
);
ctx.body = {
success: true,
data: results,
};
} catch (error) {
strapi.log.error("Multi-search API error:", error.message);
ctx.badRequest(error.message);
}
},
async stats(ctx) {
try {
const { contentType } = ctx.request.query;
const vectorService = strapi
.plugin("semantic-search")
.service("vectorService");
const stats = await vectorService.getEmbeddingStats(contentType);
ctx.body = {
success: true,
data: stats,
};
} catch (error) {
strapi.log.error("Stats API error:", error.message);
ctx.badRequest(error.message);
}
},
});2. Create Index Controller
Create the controller index (./src/plugins/semantic-search/server/src/controllers/index.js):
// Path: ./src/plugins/semantic-search/server/src/controllers/index.js
"use strict";
const searchController = require("./search-controller");
module.exports = {
searchController,
};3. Define Routes
Now define the routes (./src/plugins/semantic-search/server/src/routes/index.js):
// Path: ./src/plugins/semantic-search/server/src/routes/index.js
"use strict";
module.exports = [
{
method: "POST",
path: "/search",
handler: "searchController.search",
config: {
policies: [],
},
},
{
method: "POST",
path: "/multi-search",
handler: "searchController.multiSearch",
config: {
policies: [],
},
},
{
method: "GET",
path: "/stats",
handler: "searchController.stats",
config: {
policies: [],
},
},
];4. Create Server Index File
Finally, create the server index (server/index.js):
// Path: ./src/plugins/semantic-search/server/index.js
"use strict";
module.exports = require("./src");The API design follows REST principles with clear endpoints for different search operations. The validation ensures that malformed requests don't reach the OpenAI API, protecting both performance and costs.
Step 5: Testing and Validation
Let's test our plugin to ensure everything works correctly. First, add the embedding fields to your content types through the Strapi admin panel:
- Navigate to Content Type Builder
- Select your content type (e.g., Article)
- Add two new fields:
embedding: JSON fieldembeddingMetadata: JSON field
Restart your Strapi development server:
npm run developLook for these log messages confirming the plugin loaded correctly:
[INFO] OpenAI embedding service initialized
[INFO] Semantic Search plugin bootstrapped successfully
[INFO] Semantic Search: Validated configuration for api::article.article: title, content, summary
[INFO] Registered embedding lifecycle hooks for api::article.article with fields: title, content, summaryCreate a test article with content like:
- Title: "Getting Started with React Hooks"
- Content: "React Hooks revolutionized how we write React components..."
- Summary: "A comprehensive guide to understanding React Hooks"
When you save the article, you should see:
[INFO] Generated embedding for api::article.article document (create)Now test the search API using curl:
curl -X POST http://localhost:1337/api/semantic-search/search \
-H "Content-Type: application/json" \
-d '{
"query": "React components and hooks",
"contentType": "api::article.article",
"limit": 5
}'You should get a response like:
{
"success": true,
"data": {
"query": "React components and hooks",
"contentType": "api::article.article",
"results": [
{
"id": 1,
"title": "Getting Started with React Hooks",
"content": "React Hooks revolutionized...",
"similarityScore": 0.8945,
"createdAt": "2025-01-15T10:30:00.000Z"
}
],
"metadata": {
"totalResults": 1,
"queryProcessing": {
"embeddingDimensions": 1536
}
}
}
}Test the statistics endpoint:
curl http://localhost:1337/api/semantic-search/statsThis should return embedding coverage statistics for all your content types.
The similarity scores tell you how semantically related the results are to your query:
- 0.85-1.0: Highly relevant (direct topic match)
- 0.75-0.85: Relevant (related concepts)
- 0.65-0.75: Somewhat relevant (tangential connection)
- Below 0.65: Low relevance
Step 6: Configuration and Customization
The real power of our plugin lies in its configurability. You can customize which content types to process and which fields to extract text from.
Create a custom configuration in your config/plugins.js:
module.exports = ({ env }) => ({
"semantic-search": {
enabled: true,
resolve: "./src/plugins/semantic-search",
config: {
contentTypes: {
"api::article.article": ["title", "content", "summary", "tags"],
"api::blog.blog": ["title", "body", "excerpt", "category"],
"api::product.product": ["name", "description", "features", "benefits"],
"api::course.course": ["title", "overview", "learningOutcomes"],
},
},
},
});This configuration tells the plugin:
- Articles: Process
title,content,summary, andtags - Blog posts: Process
title,body,excerpt, andcategory - Products: Process
name,description,features, andbenefits - Courses: Process
title,overview, andlearningOutcomes
Restart Strapi and you'll see the new field mappings in the logs:
[INFO] Semantic Search: Validated configuration for api::product.product: name, description, features, benefits
[INFO] Registered embedding lifecycle hooks for api::product.product with fields: name, description, features, benefitsPerformance Optimization
For production deployments, consider these optimizations:
- Batch Processing: Process multiple documents at once during large imports
- Caching: Cache frequently searched embeddings to reduce API calls
- Database Indexing: Add indexes on frequently filtered fields
- Rate Limiting: Implement rate limiting to prevent OpenAI API overuse
Cost Management
Monitor your OpenAI usage carefully. Each embedding generation costs approximately $0.0001 per 1000 tokens. For a typical article with 1000 words, expect costs around $0.0003 per embedding.
Set up usage alerts in your OpenAI dashboard to track costs and implement caching strategies for frequently accessed content.
Demo
You can see the demo of the semantic plugin below:
GitHub Repo and Plugin Installation
The Complete source code is available on GitHub and published as an npm package: strapi-plugin-semantic-search.
Install the plugin from npm by running the command below.
npm install strapi-plugin-semantic-searchThen enable the plugin in your config/plugins.js:
module.exports = ({ env }) => ({
'semantic-search': {
enabled: true,
},
});Conclusion
The future of content discovery is semantic, and you've just built the bridge to get there. You've built a sophisticated semantic search plugin that transforms content discovery in Strapi. The system automatically generates AI embeddings for your content and provides lightning-fast search through clean REST APIs.
Next steps for extending the plugin:
- Add admin panel components for search testing
- Implement webhook support for external integrations
- Add support for image and audio content embeddings
- Integrate with external vector databases for larger datasets
- Build recommendation engines based on content similarity
This foundation enables unlimited possibilities for AI-powered content experiences. Your users will discover content they never knew existed, and you'll see the measurable impact on engagement and satisfaction.





