

£40 000 000
annual revenue
300
employees
20 years
on the market
Q1.
Tell us more about the company, what are the challenges and needs you faced?
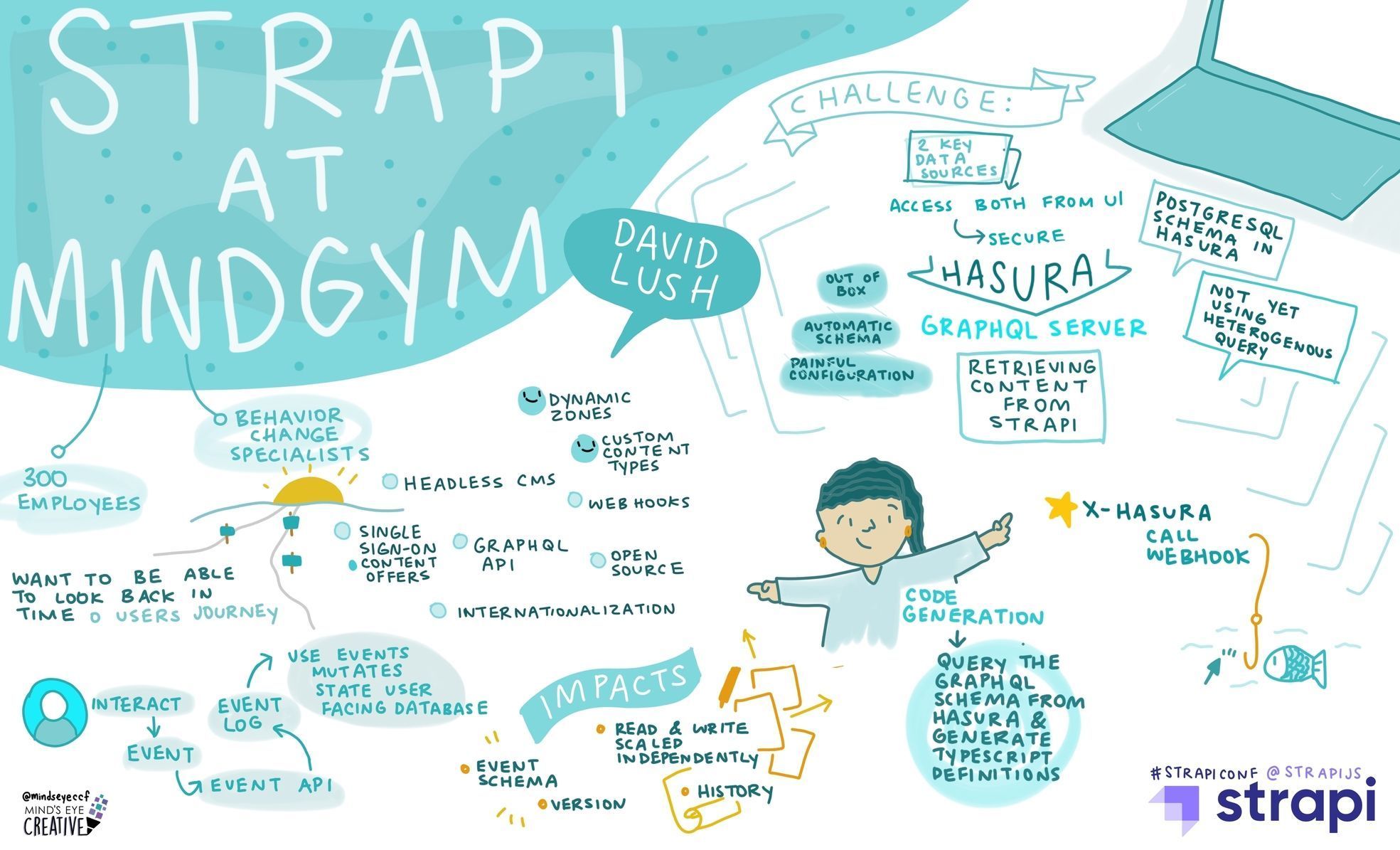
MindGym is a company with a 20-year behavior change experience with some of the world's largest brands, like Deliveroo, eBay, Uber, Cadburys, and Unilever. We do about 40 million pounds a year in revenue. We've got about 300 employees across London, New York, and Singapore, and we work with a large network of external coaches. Traditionally, our business runs on coach-led sessions of 20 to about 1500 people.
We've recently been building a new digital platform and had to make many interesting architectural decisions. The main problem we were trying to solve was serving well-structured content from our CMS.
We wanted to look back at our user's actions (temporal query). At the same time, we don't want to write lots of rigid REST API and maintain the source code that comes with that.
Q2.
Tell us more about the platform that you're building
Our platform's core uses event sourcing and CQRS (Command Query Responsibility Segregation). This gives us a separation of data flows in and out of the system. Every time a user interacts with the UI, it generates an event into our event API. Every time they click a button, scroll up the page, this is written to an event log. We also use some of these events to mutate states into a user interface and database.
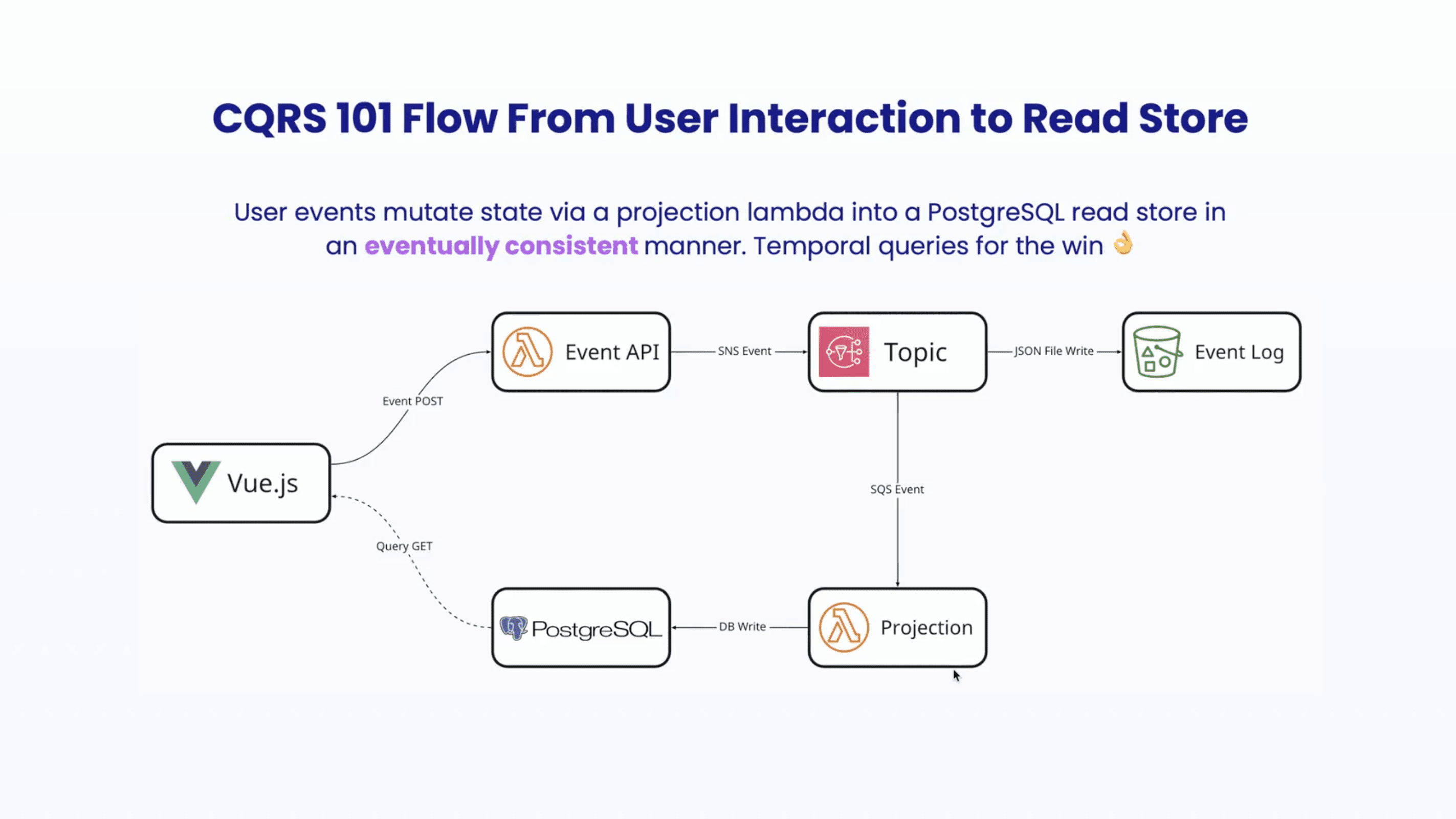
For example, if someone clicks on a button at the end of a page, this mutates to say a user has finished an exercise and progressed on their learning journey with us.
CQRS is a little bit complex to work with: you need to deal with concerns such as event schemas, versioning, and eventual consistency. However, there are positive impacts as well: read and write capacity can be scaled independently because the inbound is the very separate path from the outbound, allowing for temporal queries.
Q3.
Why did you choose Strapi?
We looked at about 40 different CMSs before landing on Strapi.
First, we shortlisted five of them and then did proof of concepts with only three of them. Some of the ** key features that brought us into Strapi **were the headless architecture, GraphQL API, Active Directory single-sign-on for our content offers internationalization, webhooks for new content and the fact that it's open-source and uses a very similar stack to the engineers that we've got in-house.
The** killer features ** really are around being able to **define custom content types and define dynamic zones ** for our content offers. We can put good guard rails around content but still allow some freedom in certain areas inside of the content model.
It also allows us to build a one-to-one relationship between the UI component library and the content schema.
Q4.
How did you implement Strapi and what other tools did you use?
We've got two key data sources in this instance: our CQRS read store and the content in Strapi. We want to access both from a UI and need this to be secure. There are a few different options for how we can tackle this.
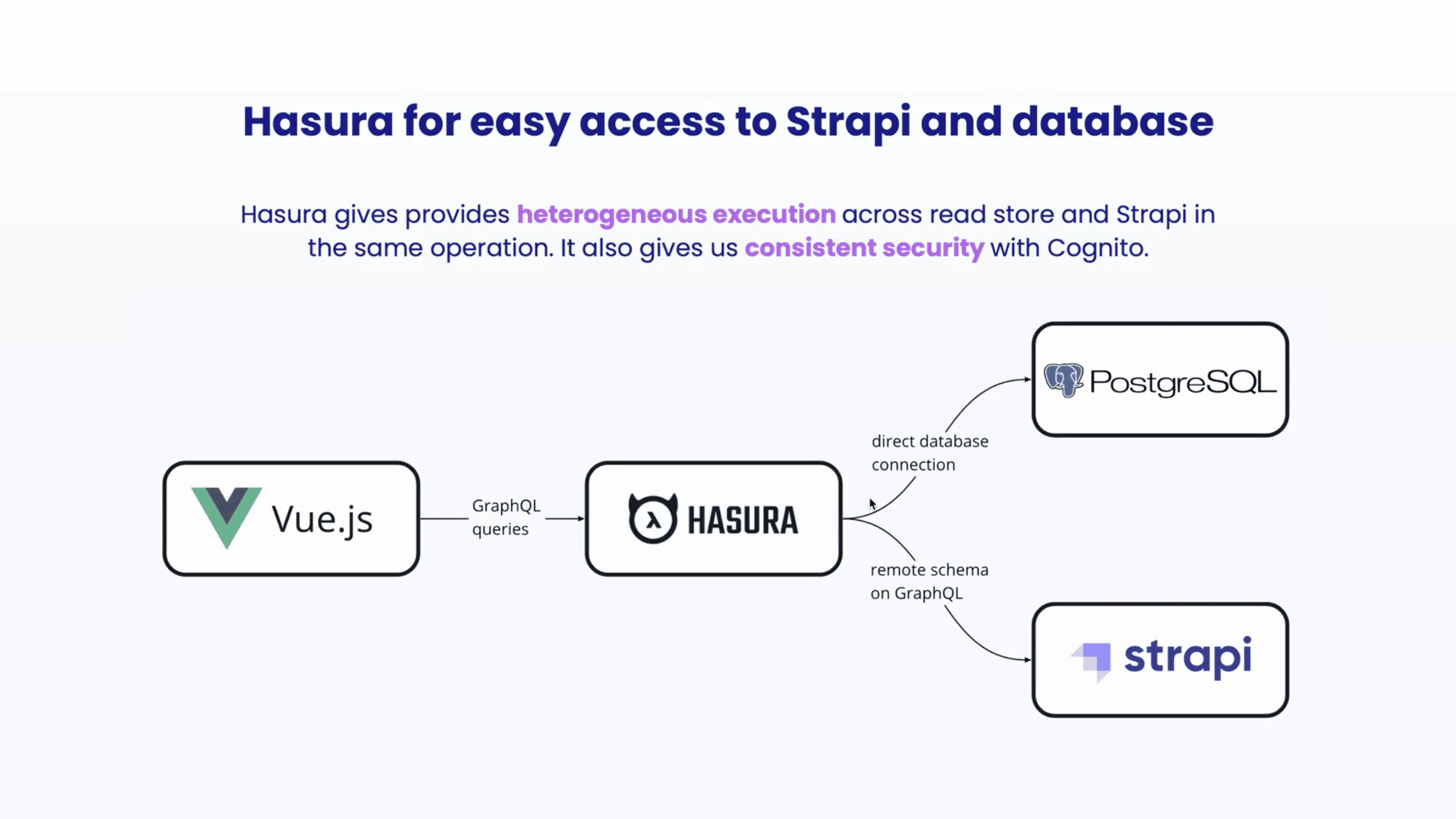
We can run some APIs for the reading store and access the read store and Strapi separately. We could put the GraphQL server on the read store and access it from above separately, but it'd be nice if there were a tool that allows federated access.
We decided to use a server as a nice open-source tool that can give this consistent access. We looked at the Apollo server on the backend, Hasura, and PostGraphile.
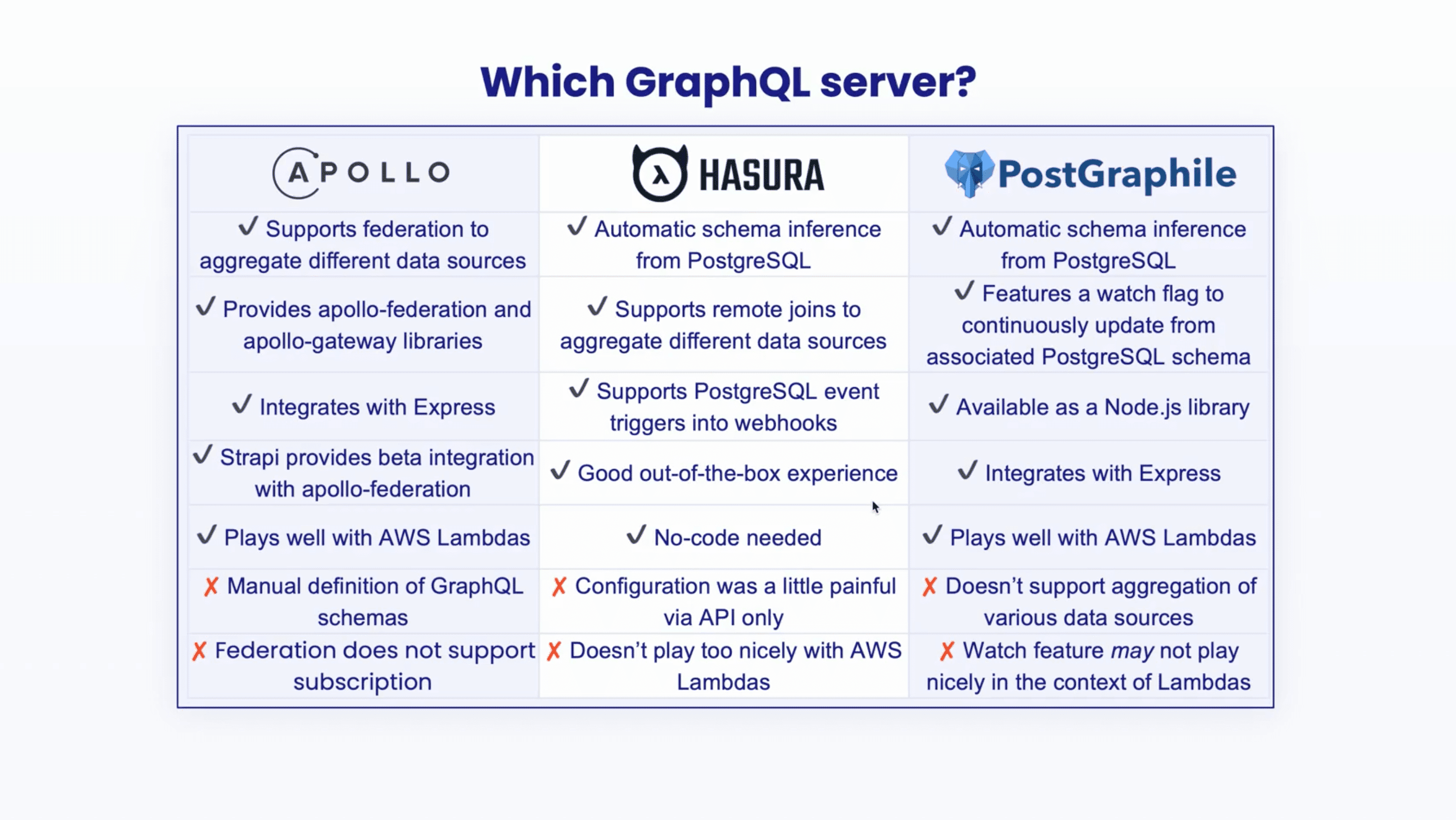
Hasura gave a nice out-of-the-box experience with no real coding required. There's automatic schema inference from PostgreSQL and automatic inference of relationships from primary and foreign key constraints in past scripts. That remote schema concept allowed us to bridge our preexisting Strapi GraphQL endpoint.
It is worth mentioning that we found the configuration a bit painful as it was all API calls rather than declarative.
Q5.
How did Strapi help you reach the goals of the project?
We're not yet at the point where we can quantify the benefits of the approach that we've taken because we're quite a new team.
We didn't have a lot of data before we started working on this, but anecdotally the ** combination of Strapi and Hasura has accelerated everything.**
It stopped us from having to write a bunch of clients from backend code that I would have done on previous projects.
With Strapi Enterprise Edition, we've been able to ship new products to market in times I haven't experienced elsewhere.
David Lush, CTO @themindgym

Scale your Strapi project as your team grows.
Unlock User roles, Audit logs, Review Workflows, and SSO authentication with our Enterprise plans. Receive support, install SSO and meet our Customer Success Manager.