

Content management systems (CMS) are software tools that help content providers manage and maintain their content efficiently. They are used for creating, updating, and managing website content. They are critical to improving the user experience and overall website speed.
In this article, you will learn how Puppeteer and Playwright compare in terms of scraping Strapi-powered web applications, you will learn about the strengths and weaknesses of each library and possible walk-around.
Prerequisites
To follow along with this tutorial and understand the code samples showcased in this article, you need to satisfy the following:
- Have Node.js (>= 16) installed on your computer.
- Have a basic understanding of CSS selectors.
- Be comfortable navigating the browser DevTools to find and select page elements.
- Have a text editor such as VSCode or any editor of choice installed on your machine.
- Basic terminal/command line knowledge to run commands for initializing projects, installing packages, deploying sites, etc.
What is Strapi?
Strapi is an open-source headless content management system (CMS) that allows users to create, manage, and expose content-rich experiences to any digital device. It offers a user-friendly interface for content managers, allowing you to manage and edit content intuitively. This flexibility makes Strapi a valuable tool for various roles within a development team.
Strapi CMS significantly reduces development time by providing pre-built functionalities like user authentication, content management, API generation, templates, and starters. Building these functionalities from scratch can be time-consuming.
For instance, a case study on the Strapi website details how Société Générale built a complex e-training application in 3 months using Strapi, which would have taken an estimated one year with traditional development.
As a developer, you can use Strapi's features not to build projects in hours/few days instead of months. With Strapi, content can be managed and delivered to any digital platform, ensuring a seamless multi-device experience for end-users.
Importance of Automation and Scraping for Strapi Applications
Puppeteer and Playwright are both web automation and testing libraries. These libraries allow you to scrape websites, and control a web browser with only a few lines of code. In terms of web scraping, both libraries have similar web scraping capabilities.
Scraping websites is important for businesses because of the following:
- Improves data collection efficiency.
- It provides real-time updates.
- Provides large datasets for data analytics
- Keeps your business ahead of the competition.
- Helps improve data quality and consistency.
- Automating these repetitive tasks can free up time for more complex tasks.
Puppeteer Vs Playwright
The effectiveness and efficiency of web scraping largely depend on the tools you use for it. Because it is unproductive and not advisable to use inefficient tools, especially for web scraping. Imagine having to install too many packages for simple functionality, worry about WebDriver and browser compatibility issues, getting easily blocked when scraping, and even more.
In this article, you will also learn how to make a better choice between the two most powerful browser automation tools available today for your web scraping needs. If you wish to use already existing web scrapers, there are tons of them available in the market such as social media scrapers like LinkedIn Job Postings Scraper.
Puppeteer and Playwright are powerful headless browser automation libraries that enable you to scrape data from websites, especially when working with Node.js-related projects for web-browser test automation. They are both useful for automating webpage interaction like clicking on buttons, and links, scrolling through pages, and even filling out forms on web pages, and ultimately, extracting data from websites.
Features of Puppeteer and Playwright for Strapi Application Automation and Scraping
Puppeteer and Playwright are both Node.js headless browser automation tools designed for end-to-end (E2E) automated testing of web applications. Because of their browser automation features, they are also used in web-scraping. Because of their great features, they are a good fit for scraping Strapi-powered web applications.
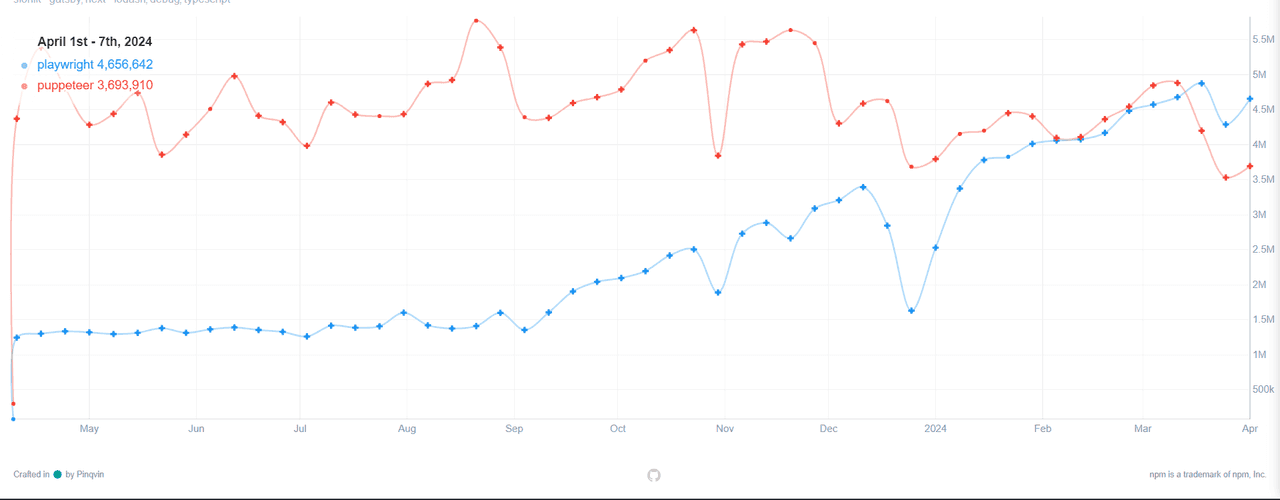
A quick look at the download trends from NPM Charts, reveals that both libraries continue to be downloaded increasingly. However, Playwright was downloaded over four million times, whereas Puppeteer was downloaded over three million times over the course of 1 week.
Both libraries are still being downloaded more and more, according to a glance at the download statistics from NPM Charts. Playwright has been downloaded more than four million times, while Puppeteer has been downloaded more than three million times in just one week.
In the next section, we will compare and contrast the different features of each library.
Web Scraping with Puppeteer
Puppeteer lets you manage headless Chrome or Chromium browsers. Puppeteer, created by Google, is a well-liked option for automating processes like as end-to-end testing and web scraping. A handful of Puppeteer's features are listed below:

Features of Puppeteer
-
Headless Browser Control: Puppeteer lets you automate a Chrome or Chromium browser without a graphical user interface. This makes it ideal for server-side environments, allowing for faster execution and efficient data processing.
-
Headless Browser Control: A Chrome or Chromium browser can be automated using Puppeteer without a graphical user interface. Because of this, it is perfect for server-side applications where data processing may be done quickly and effectively.
-
Web Scraping Efficiency: Puppeteer can swiftly scrape a lot of data because it doesn't render images. This is especially helpful for obtaining specialized data from web pages.
-
Screenshot Generation: Puppeteer's screenshot feature allows you to take pictures of web pages. This might be useful for content archiving on websites or for visual testing.
-
Flexible Element Selection: Puppeteer offers several ways to find elements on a webpage, including text selectors, custom selectors, and XPath. This guarantees you can aim for the precise information you require.
-
Chrome Extension Testing (Partially Supported): Puppeteer makes it easier to test extensions for Chrome, however, it's crucial to know that headless mode isn't supported for testing extensions because of Chrome's design limitations.
Web Scraping With Playwright
Playwright was created to make browser automation and online testing more efficient. Microsoft developed it, and it supports multiple languages and browsers, with client implementations that are both async and sync. Beyond only basic functions, it provides developers with an extensive feature set. Below are some features:

Features of Playwright
-
Cross-Browser Compatibility: Playwright comes with native support for Chromium, Firefox, and WebKit (which Safari uses), in contrast to Puppeteer. This enables you to create tests that function flawlessly in a variety of browsers.
-
Dynamic Web Page Handling: Playwright uses its auto-waiting feature to address the issues associated with dynamic websites. This ensures that your automation scripts function properly by doing away with the requirement for human waiting during testing.
-
Headful and Headless Modes: Playwright gives you the option to run browsers in both headless and headful modes, with or without a graphical user interface (GUI). While headful mode might be useful for debugging or visual reference, headless mode is best for server-side automation and site scraping.
-
Content Capture: Playwright also lets you take screen grabs, record videos of your automated tests, and create PDFs (in headless Chromium) via its page function. This adaptability makes visible feedback and thorough testing documentation possible.
-
Flexible Element Selection: Playwright facilitates the targeting of particular webpage items for interaction or data extraction by supporting standard selection methods like CSS and XPath.
-
Multi-Language Support: Playwright provides bindings for Python, Java, JavaScript, TypeScript, and .NET (C#) to cater to a broader development community.
-
Proxy Integration: When performing online automation operations, Playwright gives you the ability to use proxies to get more control.
Feature Comparison of Playwright and Puppeteer
Language Support
Compared to Puppeteer, which only supports JavaScript, Playwright offers cross-language support for Python, JavaScript/TypeScript,.NET, and Java. Nevertheless, Puppeteer has an unauthorized Python support program named Pyppeteer. This is helpful if you want to use Playwright for scraping since, if you're not comfortable with JavaScript, you're not limited to a specific language.
Browser Support
If cross-browser compatibility is not a concern for you, using Playwright for your scraping needs is also helpful in terms of browser support. This is due to Playwright's native support for Firefox, WebKit (Safari), Chrome, and Chromium-based browsers. Playwright is a versatile option for projects requiring cross-browser testing or automation in non-Chromium environments because of the wide range of supported browsers.
Conversely, Puppeteer was created by the Google Chrome team and is limited to Chromium-based browsers and Google Chrome (with experimental support for Firefox and Edge). The original plan was to automate browsers that ran on the Chromium platform. Puppeteer is therefore a fantastic option for applications where Chromium compatibility is crucial.
Community Support
Compared to Puppeteer, which has been in the market since 2017, Playwright is somewhat new to the community, having only been introduced in 2020. This corresponds to the variations in community size that have been noted.
As of April 2024, Puppeteer boasts of 86k+ GitHub stars, whereas Playwright has about 61k+ GitHub stars. When it comes to community, Puppeteer has a large following, while Playwright has a small but active one.
Speed
Both Puppeteer and Playwright are renowned for their rapidity and effectiveness. The Playwright, however, has a few advantages that might provide it a little advantage in particular situations.
Playwright's auto-waiting function is one important distinction. By simulating human behavior and automating waiting periods following tasks like form completion, this functionality may lower the possibility of a bot being discovered. The manual timer configuration required by Puppeteer may increase complexity and slow down scraping.
Playwright's synchronous and asynchronous client support is another aspect. While synchronous clients are simpler for smaller scripts, asynchronous clients are best for scaling complicated scraping jobs. Since Puppeteer only enables asynchronous clients, Playwright gives greater customization options for optimizing scraping performance by project requirements.
Auto-Waiting Mechanism
Playwright auto-waiting function removes the need for manually setting timers in your scraping scripts. Playwright automatically performs a series of checks to ensure elements are visible, stable, and responsive before attempting any actions like clicking or filling out forms. This not only simplifies your code but also helps avoid errors caused by interacting with elements that aren't fully loaded or ready thereby preventing flaky tests.
In Puppeteer, you can use the page.waitForSelector() method to wait for the selector to appear on the page. If at the moment of calling the method the selector already exists, the method will return immediately. If the selector doesn't appear after the timeout milliseconds of waiting, the function will throw an error.
Usability for Strapi Content Scraping
When it comes to scraping content from Strapi-powered applications, both Puppeteer and Playwright are great libraries for browser automation and testing, however, there are minor differences that you should be aware of.
In the next section, I will summarize all the feature comparisons and differences between both libraries in a table.
Tabular Comparison of Playwright vs. Puppeteer Features
| Feature | Puppeteer | Playwright |
|---|---|---|
| Language Support | JavaScript/TypeScript (unofficial Python port: Pyppeteer) | Python, Java, JavaScript/TypeScript, C#, .NET |
| Browser Support | Chrome/Chromium (limited Firefox/Edge support) | Chrome/Chromium, WebKit (Safari), Firefox |
| Waiting Mechanism | Manual timer setup (e.g., page.waitForSelector()) | Auto-waiting for elements to be ready before interaction |
| Community & Documentation | Larger, established community | Growing community, good documentation, but not as extensive as Puppeteer |
| Strapi Automation | Suitable for basic tasks like login, form filling, and content creation | More flexible for complex workflows due to multi-language support and potential browser emulation for responsive UI testing |
| Strapi Scraping | Efficient for scraping Chrome/Chromium-based Strapi applications | Ideal for scraping Strapi applications across various browsers to ensure data consistency |
| Ease of Use | Generally easier to start with due to larger community resources | Might have a slightly steeper learning curve for those new to the tool |
| Integration with Strapi API | Both can be integrated with Strapi's official REST API for data manipulation | ✅ |
| Error Handling | Provides error handling mechanisms for unexpected scenarios | Offers similar error handling capabilities |
| Performance | Known for fast scraping speeds | Offers similar performance, especially for Chrome/Chromium scraping |
| Scalability | Scales well for large-scale scraping projects | Scales well due to asynchronous client support |
Getting Started with Scraping a Strapi Application
In this section, I will walk you through how to scrape Strapi-powered web applications using both Puppeteer and Playwright, so you see them in action. For this article, I will be scraping the L'Équipe.fr website. The L'Équipe.fr website is powered by Strapi CMS; therefore, I will be using it for our scraping purposes.
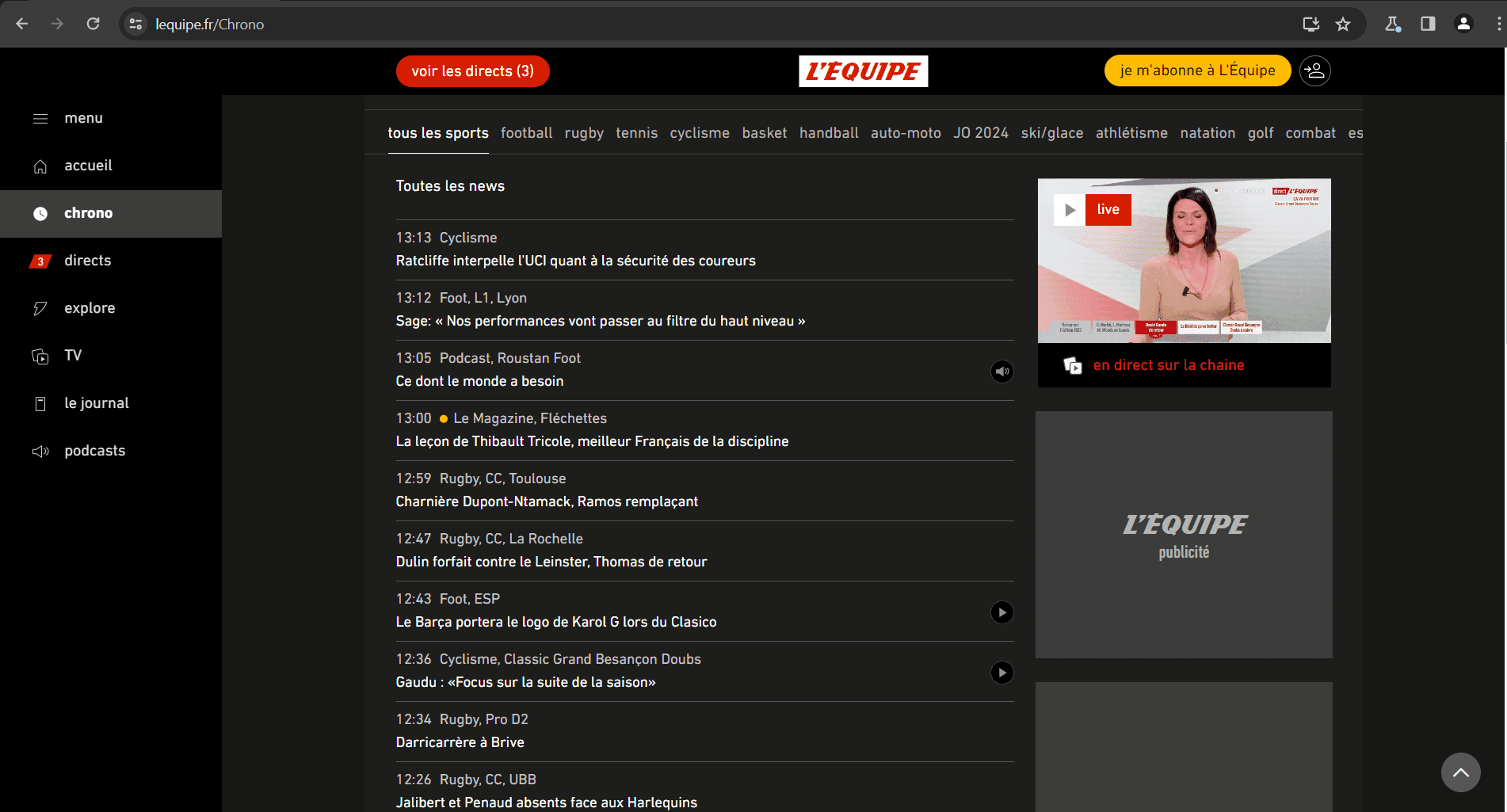
Using DevTools to Inspect L'Équipe.fr
I will use the Chrome browser DevTools to inspect the L'Équipe.fr to know the elements I will target to extract data. To open Chrome DevTools, you can press F12 or right-click anywhere on the page and choose Inspect.
Now go to L'Équipe.fr and open your DevTools there. Inspecting the same website as I will make this article easier to follow.
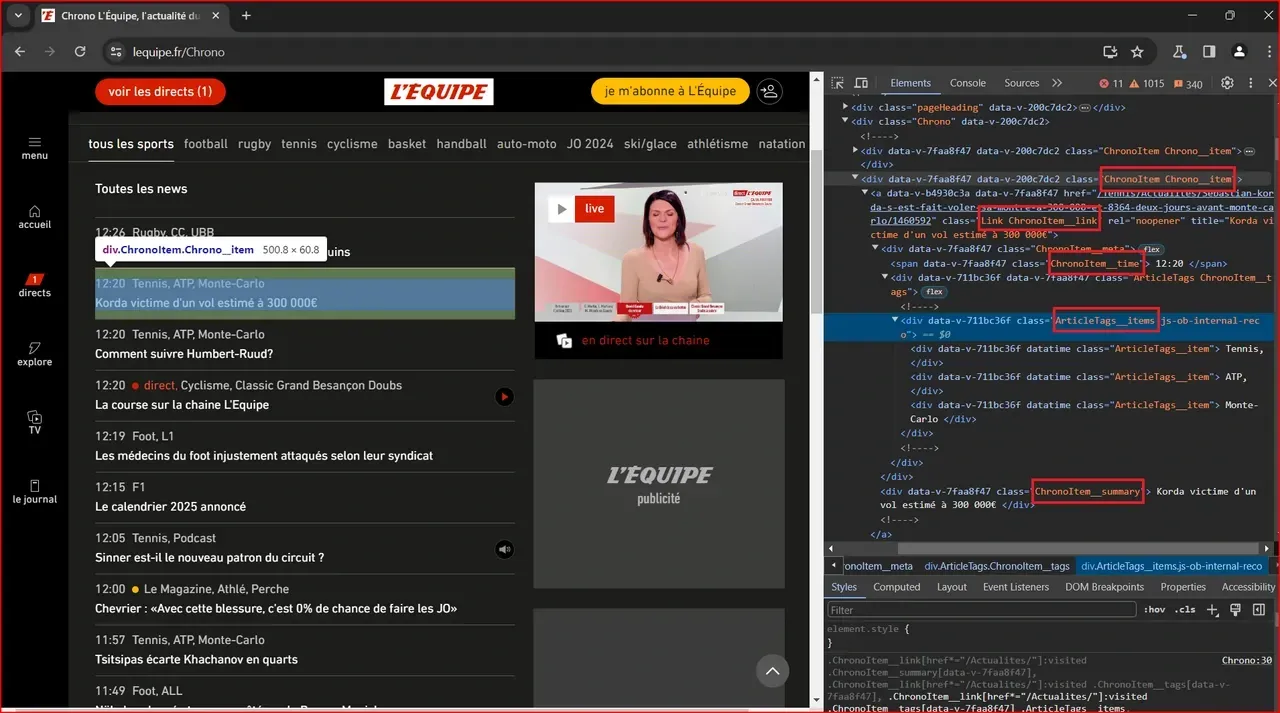
I will start by walking you through how to build your scraper using Puppeteer first, then Playwright.
Scraping a Strapi-Powered Application using Puppeteer: Code Examples
The first step is to create a folder. In this case, I will name my folder puppeteer-scraper. Run the command below to create your folder and cd into this newly created folder.
mkdir puppeteer-scraper && cd puppeteer-scraperNext, initialize an empty Node.js project by running this command:
npm init -yNow, you need to install the Puppeteer library. Run this command to install Puppeteer:
npm install puppeteerAfter typing this command, you should find this package.json file in your project folder.
To get started, let's make sure your project can understand modern JavaScript (ES6 features) by adding "type": "module" to your package.json file.
{
"name": "puppeteer-scraper",
"version": "1.0.0",
"type": "module",
"description": "",
"main": "index.js",
"scripts": {
"test": "echo \"Error: no test specified\" && exit 1"
},
"keywords": [],
"author": "",
"license": "ISC",
"dependencies": {
"puppeteer": "^22.6.3"
}
}After installing Puppeteer, next, create an index.js file in the root folder. This will serve as an entry point to your scraper application. Inside the index.js file, paste the following code:
import puppeteer from "puppeteer";
const getPosts = async () => {
// Start a Puppeteer session with:
// - a visible browser (`headless: false` - easier to debug because you'll see the browser in action)
// - no default viewport (`defaultViewport: null` - website page will be in full width and height)
const browser = await puppeteer.launch({
headless: false,
defaultViewport: null,
});
// Open a new page
const page = await browser.newPage();
// On this new page:
// - open the "https://www.lequipe.fr/Chrono" website
// - wait until the dom content is loaded (HTML is ready)
await page.goto("https://www.lequipe.fr/Chrono", {
waitUntil: "domcontentloaded",
});
};
// Start the scraping
getPosts();Now, it is time to run our application, so we see what we have so far. To run your application, run the following command:
node index.jsThis will spin up Chrome in a headful browser with a new page and the L'Équipe.fr loaded onto it, just like in the screenshot below:
Next, update your index.js file with this code:
import puppeteer from "puppeteer";
(async () => {
// Launch a headless browser (change to headless: false for debugging)
const browser = await puppeteer.launch({ headless: false });
// Open a new page
const page = await browser.newPage();
// Navigate to the L'Équipe.fr page
await page.goto('https://www.lequipe.fr/Chrono');
// Pause for `.ChronoItem`
await page.waitForSelector('.ChronoItem');
// Wait for at least 5 article cards to be loaded
await page.waitForFunction(() => {
const articleCards = document.querySelectorAll(".ChronoItem");
return articleCards.length > 5;
});
// Get page data
const scrapedPosts = await page.evaluate(() => {
const articleCards = document.querySelectorAll('.ChronoItem');
return Array.from(articleCards).map((card) => {
const link = card.querySelector(".Link.ChronoItem__link")?.href || null;
const time = card.querySelector(".ChronoItem__time").innerText?.trim() || null;
const summary = card.querySelector(".ChronoItem__summary").innerText?.trim() || null;
const tags = card.querySelectorAll(".ArticleTags__item").innerText?.trim()?.split(",") || null;
return { link, time, summary, tags };
});
});
// Display scraped posts
console.log("Scraped posts from current page:", scrapedPosts);
// Close the browser
await browser.close();
})();
In the code above, you started a Puppeteer session with:
- a visible browser (
headless: false- easier to debug because you'll see the browser in action) - no default viewport (
defaultViewport: null- website page will be in full width and height) - The
index.jsfile uses Puppeteer to launch a headless browser (invisible) and opens a new page. - It navigates to the target website (L'Équipe.fr in this example) and waits for the content to load.
- The script then enhances the scraping logic by waiting for specific elements to appear, ensuring targeted data is available.
- It extracts data using
page.evaluatefunction which injects JavaScript code into the browser to query the DOM (Document Object Model) for elements containing article links, time, summaries, and tags. - Finally, the scraped data is logged into the console, and the browser is closed.
Now, stop the server by pressing CTRL + C and then start the server once more by running the command below:
node index.jsResult of Scraping with Puppeteer
This result of scraping the L'Équipe.fr website using Puppeteer is shown below:
[
{
"link": "https://www.lequipe.fr/Tennis/Actualites/Ugo-humbert-apres-son-elimination-en-quarts-de-finale-a-monte-carlo-je-vais-tout-faire-pour-me-rapprocher-du-top-10/1460777",
"time": "21:21",
"summary": "Humbert : «Tout faire pour me rapprocher du top 10»",
"tags": null
},
{
"link": "https://www.lequipe.fr/Rugby/Actualites/Pro-d2-vannes-et-beziers-vainqueurs-avec-le-bonus-grenoble-cartonne/1460776",
"time": "21:16",
"summary": "Vannes, Béziers et Grenoble vainqueurs avec le bonus",
"tags": null
},
{
"link": "https://www.lequipe.fr/Jo-2024-paris/Cyclisme-sur-piste/Actualites/Les-francaises-de-la-poursuite-par-equipes-qualifiees-pour-les-jo-2024/1460773",
"time": "21:12",
"summary": "La poursuite par équipes féminine qualifiée",
"tags": null
},
{
"link": "https://www.lequipe.fr/Rugby/Actualites/Ronan-o-gara-entraineur-de-la-rochelle-mon-president-ne-m-a-pas-choisi-pour-emmener-mes-joueurs-visiter-mon-ancienne-ecole/1460769",
"time": "21:01",
"summary": "O'Gara : «Pas emmener mes joueurs visiter mon ancienne école»",
"tags": null
}
]Check out the complete code repository on GitHub.
Scraping a Strapi-Powered Application using Playwright: Code Examples
The first step is to create a folder. In this case, I will name my folder puppeteer-scraper. Run this command to create your folder and cd into it.
mkdir playwright-scraper && cd playwright-scraperNext, initialize an empty project by running this command:
npm init -yNow, you need to install the Playwright library. Run this command to install Playwright:
npm install playwright && npx playwright installAfter typing this command, you should find this package.json file at the root of your project.
To get started, let's make sure your project can understand modern JavaScript (ES6 features) by adding "type": "module" to your package.json file.
{
"name": "playwright-scraper",
"version": "1.0.0",
"type": "module",
"description": "",
"main": "index.js",
"scripts": {
"test": "echo \"Error: no test specified\" && exit 1"
},
"keywords": [],
"author": "",
"license": "ISC",
"dependencies": {
"playwright": "^1.43.1"
}
}After installing Playwright, next, create an index.js file in the root folder. This will serve as an entry point to your scraper application. Inside it, paste the following code:
// Import the Chromium browser into our scraper.
import { chromium } from 'playwright';
// Open a Chromium browser. We use headless: false
// to be able to watch the browser window.
const browser = await chromium.launch({
headless: false
});
// Open a new page/tab in the browser.
const page = await browser.newPage();
// Tell the tab to navigate to the JavaScript topic page.
await page.goto('https://www.lequipe.fr/Chrono');
// Pause to see what's going on.
await page.waitForTimeout(120_000);
// other codes go here
// Close the browser to clean up after ourselves.
await browser.close();This will spin up Chrome in a headful browser with a new page and the L'Équipe.fr loaded onto it, just like in the screenshot below:
Up until now, you have not yet started scraping the website. The code above is to make sure Playwright is running as expected.
Next, add the following snippet where I added the comment // other codes go here above:
...
await page.waitForFunction(() => {
// Find all article card elements (consider a more generic selector if needed)
const articleCards = document.querySelectorAll(".ChronoItem");
return articleCards.length > 5;
});
// Get page data
const scrapedPosts = await page.$$eval('.ChronoItem", (articleCards) => {
return articleCards.map(card => {
// Fetch the sub-elements from the previously fetched quote element
const link = card.querySelector(".Link.ChronoItem__link")?.href || null;
const time = card.querySelector(".ChronoItem__time").innerText?.trim() || null;
const summary = card.querySelector(".ChronoItem__summary").innerText?.trim() || null;
const tags = card.querySelectorAll(".ArticleTags__item").innerText?.trim()?.split(",") || null;
return {
link,
time,
summary,
tags
};
});
});
// Add scraped posts from this page
console.log("Scraped posts from current page:", scrapedPosts);
// Pause to see what's going on.
await page.waitForTimeout(120_000);
...The code above uses the Playwright library to scrape data from the L'Équipe.fr website. You make use of a headless Chromium browser, allowing you to control the process without a physical browser window. First, it launches the browser and opens a new page, navigating to the target URL (https://www.lequipe.fr/Chrono). A wait is implemented to ensure the page fully loads.
Then, the code employs a function to wait for specific conditions on the page. In this case, it waits until at least six elements match the .ChronoItem selector, representing article cards. Once met, the script extracts data using page evaluation. It finds all elements matching .ChronoItem and iterates through them, building an object for each containing detail like the link, time, summary, and tags. These objects are collected into an array and printed to the console.
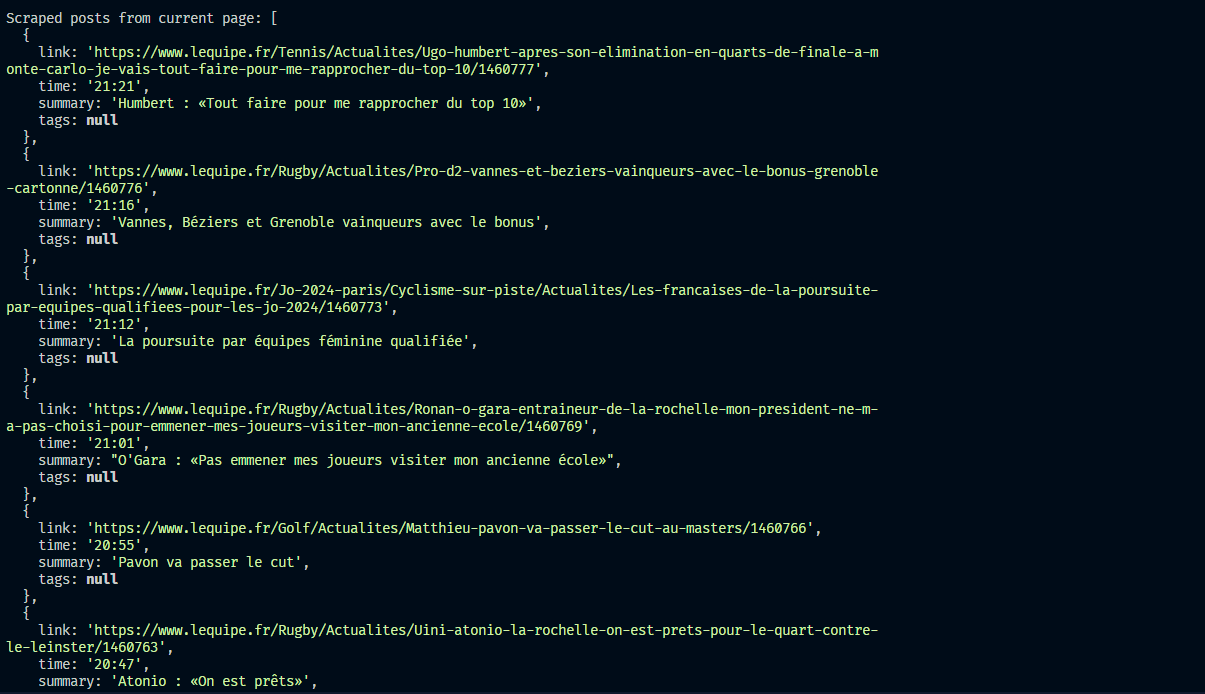
Result of Scraping with Playwright
[
{
"link": "https://www.lequipe.fr/Tennis/Actualites/Ugo-humbert-apres-son-elimination-en-quarts-de-finale-a-monte-carlo-je-vais-tout-faire-pour-me-rapprocher-du-top-10/1460777",
"time": "21:21",
"summary": "Humbert : «Tout faire pour me rapprocher du top 10»",
"tags": null
},
{
"link": "https://www.lequipe.fr/Rugby/Actualites/Pro-d2-vannes-et-beziers-vainqueurs-avec-le-bonus-grenoble-cartonne/1460776",
"time": "21:16",
"summary": "Vannes, Béziers et Grenoble vainqueurs avec le bonus",
"tags": null
},
{
"link": "https://www.lequipe.fr/Jo-2024-paris/Cyclisme-sur-piste/Actualites/Les-francaises-de-la-poursuite-par-equipes-qualifiees-pour-les-jo-2024/1460773",
"time": "21:12",
"summary": "La poursuite par équipes féminine qualifiée",
"tags": null
},
{
"link": "https://www.lequipe.fr/Rugby/Actualites/Ronan-o-gara-entraineur-de-la-rochelle-mon-president-ne-m-a-pas-choisi-pour-emmener-mes-joueurs-visiter-mon-ancienne-ecole/1460769",
"time": "21:01",
"summary": "O'Gara : «Pas emmener mes joueurs visiter mon ancienne école»",
"tags": null
}
]This scraped data from the L'Équipe.fr website is a collection of sports news containing a summary of the news, a link to read the full post, and tags.
Check out the complete code repository on GitHub.
Legality of Scraping Websites
Web scraping legality can be complex. Below are important tips to keep in mind while scraping.
- Respect robots.txt and terms of service: Always check a website's robots.txt file and terms of service to see if scraping is allowed. Scraping data that goes against these guidelines can be illegal.
- Consider data privacy regulations: Regulations like GDPR (Europe) and CCPA (California) may apply depending on your location and the type of data you scrape. Make sure you understand and comply with these regulations.
- Focus on publicly available data: While scraping public information like blog postings might be okay, extracting personal details requires a valid justification. When in doubt, consult a lawyer.
- Employ strategies and means to avoid getting blocked while scraping.
Conclusion
Both Puppeteer and Playwright are great automation libraries for scraping. The best choice depends on your specific needs. Web scraping with Puppeteer remains a strong option for its ease of use, extensive documentation, and focus on Chrome/Chromium, which might be sufficient for many Strapi CMS projects. However, web scraping with Playwright's multi-language support, auto-waiting functionality, and cross-browser capabilities offer a more versatile and potentially future-proof solution, especially for complex workflows or scraping across multiple browsers.





